الگوریتم هوش مصنوعی رشتهای است که در آن میخواهیم کامپیوترها کارهایی را انجام دهند که انسانها انجام میدهند. بدیهی است که کامپیوترها در محاسبه و تواناییهای تحلیلی سریعتر هستند، اما کامپیوترها نمیتوانند به تنهایی تصمیم بگیرند، یعنی توانایی تصمیم گیری را ندارند. توانمندسازی رایانهها برای تصمیم گیری با هوش خود، هوش مصنوعی است. حال سؤال این است که چگونه میتوان این کار را انجام داد؟ در اینجا با الگوریتمهای هوش مصنوعی مواجه میشویم. این الگوریتمهای ویژه قادر به یافتن الگوها و ارائه فرآیندی برای تصمیم گیری هستند. این الگوریتمهای هوش مصنوعی در زمینههای متنوعی مانند رباتیک، بازاریابی، تجزیه و تحلیل تجاری، کشاورزی، مراقبتهای بهداشتی و …کاربرد دارند و انقلاب صنعتی جدیدی را پیشروی انسانهای قرار دادهاند. در این مطلب به بررسی پرکاربردترین الگوریتمهای هوش مصنوعی میپردازیم.
فهرست مطالب:
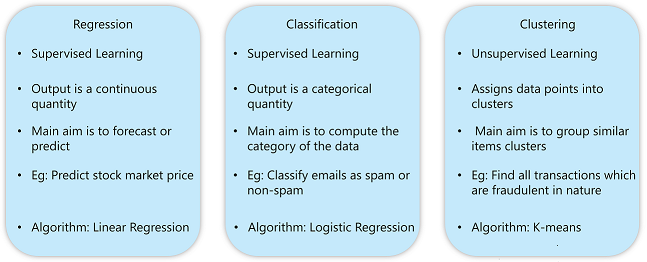
دستهبندی مسائلی که الگوریتمهای هوش مصنوعی حل میکند
دستهبندی مسائلی که الگوریتمهای هوش مصنوعی حل میکند
الگوریتمهای هوش مصنوعی در هر دستهای که طبقهبندی شده باشند، در اصل، کار یکسانی را برای پیشبینی خروجیها با ورودیهای ناشناخته انجام میدهند، با این حال، در این دستهبندی دادهها محرک کلیدی هنگام انتخاب الگوریتم مناسب هستند. در اینجا جدولی وجود دارد که به طور مؤثر با توجه به مسائل نوع الگوریتمها را طبقهبندی کرده است. در هر دسته از وظایف، میتوانیم از الگوریتمهای خاصی استفاده کنیم. در ادامه این مطلب خواهید فهمید که چگونه یک دسته از الگوریتمها میتوانند به عنوان راه حلی برای مسائل پیچیده استفاده شوند.
Classification Algorithms
ایده الگوریتمهای طبقهبندی بسیار ساده است. در این الگوریتم شما مشخصات هدف ( Target class) را با تجزیه و تحلیل مجموعه دادههای آموزشی پیشبینی میکنید. این یکی از مهمترین، اگر نگوییم ضروریترین مفاهیم و الگوریتمهایی است که هنگام یادگیری علم داده باید به آن تسلط داشته باشید.بر اساس داده های آموزشی، Classification Algorithms یک تکنیک یادگیری نظارت شده است که برای طبقه بندی مشاهدات جدید استفاده می شود. در دستهبندی، یک برنامه از مجموعه داده یا مشاهدات ارائه شده برای یادگیری نحوه طبقه بندی مشاهدات جدید در گروههای مختلف استفاده می کند. به عنوان مثال، 0 یا 1، قرمز یا آبی، بله یا خیر، هرزنامه (Spam) یا عدم هرزنامه، و… اهداف، برچسبها یا دستهها همه میتوانند برای توصیف انواع دادهها استفاده شوند. الگوریتم طبقهبندی از دادههای ورودی برچسبدار استفاده میکند، زیرا یک تکنیک یادگیری تحت نظارت است و شامل اطلاعات ورودی و خروجی است. یک تابع خروجی گسسته (y) در فرآیند طبقه بندی (x) به متغیر ورودی منتقل میشود. به عبارت ساده، Classification Algorithms نوعی تشخیص الگو است که در آن الگوریتمهای طبقهبندی بر روی دادههای آموزشی برای کشف الگوی مشابه در مجموعههای داده جدید انجام میشود.
کاربردهای الگوریتمهای Classification
- طبقه بندی Spam E _mail
- پیشبینی تمایل به پرداخت وام مشتریان بانک
- شناسایی سلول های تومور سرطانی
- تحلیل احساسات
- طبقه بندی داروها
- تشخیص نقاط چهره
- تشخیص عابران پیاده در رانندگی خودروهای سواری
انواع الگوریتمهای طبقهبندی
الگوریتمهای طبقه بندی را میتوان به طور کلی به صورت زیر طبقهبندی کرد:
طبقه بندی کنندههای خطی (Linear Classifiers):
رگرسیون لجستیک (Logistic regression)
طبقهبندیکننده ساده بیز(Naive Bayes classifier)
تشخیص خطی فیشر(Fisher’s linear discriminant)
ماشینهایبردار پشتیبانی (ٰSupport vector machines):
Least squares support vector machines
طبقهبندیهای درجه دوم (Quadratic classifiers)
تخمین کرنل (Kernel estimation)
k-نزدیکترین همسایه (k-nearest neighbor)
درختان تصمیم(Decision trees)
شبکههای عصبی (Neural networks)
آموزش کوانتیزاسیون برداری (Learning vector quantization)
Naive Bayes
الگوریتم ساده بیز از قضیه بیز پیروی می کند که بر خلاف سایر الگوریتم های این لیست، از رویکرد احتمالی پیروی می کند. این به این معنی است که به جای پرش مستقیم به داده ها، الگوریتم مجموعه ای از احتمالات قبلی را برای هر یک از کلاس ها برای هدف شما تنظیم می کند.هنگامی که داده ها را به هوش مصنوعی ارائه می کنید، الگوریتم این احتمالات قبلی را به روز می کند تا چیزی به نام احتمال پسین را تشکیل دهد. Naive Bayes ساده لوح نامیده می شود زیرا فرض می کند که هر متغیر ورودی مستقل است. این یک فرض قوی و غیر واقعی برای داده های واقعی است. با این حال، این تکنیک در طیف وسیعی از مشکلات پیچیده بسیار موثر است. طبقه بندی کننده های ساده بیز مجموعه ای از الگوریتم های طبقه بندی بر اساس قضیه بیز هستند. این یک الگوریتم واحد نیست، بلکه خانواده ای از الگوریتم ها است که در آن همه آنها یک اصل مشترک دارند، یعنی هر جفت ویژگی طبقه بندی شده مستقل از یکدیگر است. برای شروع، اجازه دهید یک مجموعه داده را در نظر بگیریم. یک مجموعه داده خیالی را در نظر بگیرید که شرایط آب و هوایی را برای بازی گلف توصیف می کند.
با توجه به شرایط آب و هوایی، هر شرایط را به عنوان مناسب (“بله”) یا نامناسب (“نه”) برای بازی گلف طبقه بندی می کند. با استفاده از این فرکانس ها، احتمالات اولیه خود را تولید می کنیم (به عنوان مثال، احتمال ابری 0.29 است در حالی که احتمال عمومی بازی 0.64 است). در مرحله بعد، احتمالات پسینی را ایجاد می کنیم، جایی که سعی می کنیم به سوالاتی مانند “احتمال اینکه بیرون آفتابی باشد و فرد گلف بازی کند چقدر است؟” پاسخ دهیم.
ما در اینجا از فرمول بیزی استفاده می کنیم:
P(بله | آفتابی) = P( آفتابی | بله) * P(بله) / P (آفتابی)
در اینجا P (آفتابی | بله) = 3/9 = 0.33، P (آفتابی) = 5/14 = 0.36، P (بله) = 9/14 = 0.64 داریم.
Decision Tree
درخت تصمیم یک الگوریتم یادگیری ماشین نظارت شده است که شبیه یک درخت معکوس است، که در آن هر گره نشان دهنده یک متغیر پیش بینی کننده (ویژگی)، پیوند بین گره ها نشان دهنده یک تصمیم و هر گره برگ نشان دهنده یک نتیجه (متغیر پاسخ) است. درخت تصمیم نقشهای از نتایج احتمالی مجموعهای از انتخابهای مرتبط به یکدیگراست. مهمترین کاربرد درخت تصمیمگیری این است که به یک فرد یا سازمان این امکان را میدهد تا اقدامات احتمالی را بر اساس هزینهها، احتمالات و منافع خود در برابر یکدیگر ارزیابی کند. همانطور که از نامش پیداست، از یک مدل درخت مانند از تصمیمات استفاده می کند. درخت تصمیم اساساً می تواند به عنوان یک ساختار درختی فلوچارت مانند خلاصه شود که در آن هر گره خارجی آزمایشی را بر روی یک ویژگی نشان می دهد و هر شاخه نشان دهنده نتیجه آن آزمایش است. گره های برگ حاوی برچسب های واقعی پیش بینی شده هستند. ما از ریشه درخت شروع می کنیم و به مقایسه مقادیر ویژگی ها ادامه می دهیم تا به یک گره برگ برسیم. ما از این طبقه بندی کننده در هنگام مدیریت داده های با ابعاد بالا و زمانی که زمان کمی برای آماده سازی داده ها صرف شده است استفاده می کنیم.
نکتهای که باید هنگام انتخاب و استفاده از الگوریتم درخت تصمیمگیری به آن دقت کنید این است که با کوچکترین تغییر جزئی در اطلاعات تمام نتایج و طبقهبندی دادهها به طور کلی زیر و رو خواهد شد.
ساختار کلی الگوریتم درخت تصمیمگیری
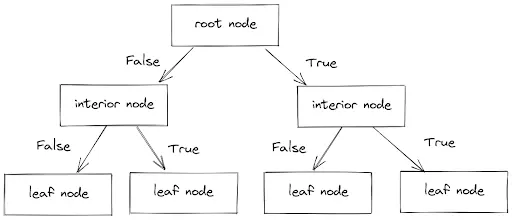
یک درخت تصمیم دارای ساختار زیر است:
گره ریشه: گره ریشه نقطه شروع یک درخت است. در این مرحله اولین تقسیم انجام می شود.
گره های داخلی: هر گره داخلی نشان دهنده یک نقطه تصمیم (متغیر پیش بینی) است که در نهایت منجر به پیش بینی نتیجه می شود.
گره های برگ / پایانی: گره های برگ نشان دهنده کلاس نهایی نتیجه هستند و بنابراین به آنها گره های پایان دهنده نیز می گویند.
شاخه ها: شاخه ها اتصالات بین گره ها هستند، آنها به صورت فلش نشان داده می شوند. هر شاخه نشان دهنده پاسخی مانند بله یا خیر است.
مزایای استفاده از الگوریتم درخت تصمیمگیری
۱- الگوریتمهای درخت تصمیمگیری قوانین قابل درک متناسب با منطق انسانی را ارائه میدهند.
۲- الگوریتمهای درخت تصمیم بدون نیاز به محاسبات زیاد حجم طبقه بندی قابلتوجهای را انجام میدهند.
۳- درختهای تصمیمگیری قادر به مدیریت وآنالیز متغیرهای پیوسته و طبقهای هستند.
۴- درختان تصمیمگیری نشان میدهند که کدام زمینهها و فاکتورها برای پیشبینی یا تصمیمگیری مهمتر هستند.
معایب استفاده از الگوریتم درخت تصمیمگیری
۱ـ درختهای تصمیم برای کارهای تخمینی که هدف آن پیشبینی ارزش یک ویژگی پیوسته است، کمتر مناسب هستند.
۲ـ درختهای تصمیم مستعد خطا در مسائل طبقهبندی با دستههای دادههای زیاد و تعداد نسبتاً کمی مثالهای آموزشی هستند.
۳ـ آموزش و فرآیند رشد درخت تصمیم از نظر محاسباتی الگوریتمی هزینهبراست.
Random Forest
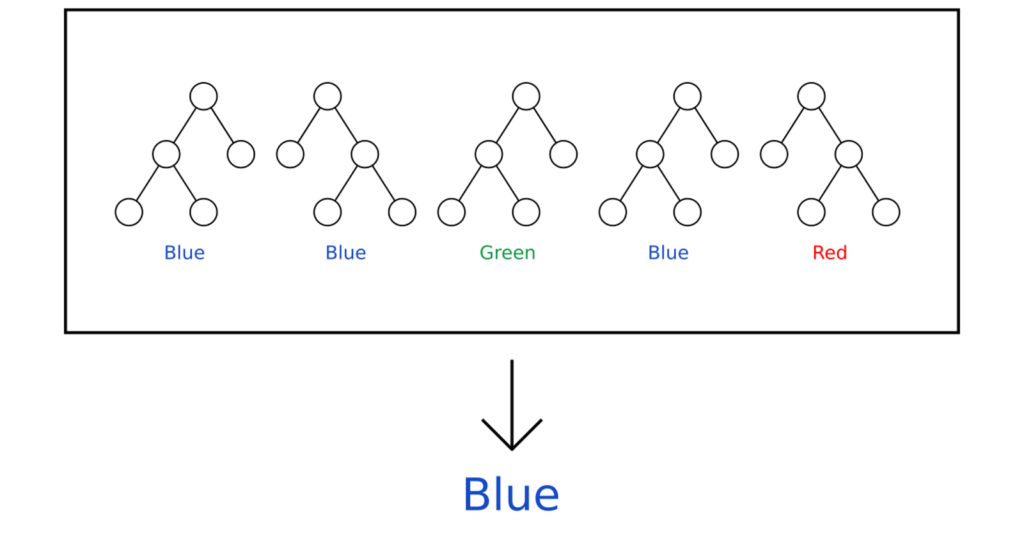
یک الگوریتم یادگیری ماشینی نظارت شده است که به طور گسترده در مسائل طبقه بندی و رگرسیون استفاده می شود. درخت های تصمیم را بر روی نمونه های مختلف می سازد و اکثریت آن ها را برای طبقه بندی و در صورت رگرسیون میانگین می گیرد.Random Forest می تواند هر دو وظایف رگرسیون و طبقه بندی را انجام دهد. این الگوریتم پیش بینی های خوبی تولید می کند که به راحتی قابل درک است. می تواند مجموعه داده های بزرگ را به طور موثر اداره کند. الگوریتم جنگل تصادفی سطح بالاتری از دقت را در پیشبینی نتایج نسبت به الگوریتم درخت تصمیم ارائه میکند.
همانطور که در تصویر می بینیم، ما 5 درخت تصمیم داریم که سعی می کنند یک رنگ را طبقه بندی کنند. در اینجا 3 مورد از این 5 درخت تصمیم آبی را پیشبینی میکنند و دو درخت خروجی متفاوتی دارند، یعنی سبز و قرمز. در این حالت، میانگین تمام خروجی ها را می گیریم که آبی را به عنوان بالاترین نشان می دهد.
Logistic Regression
رگرسیون لجستیک نمونه ای از یادگیری تحت نظارت است. برای محاسبه یا پیش بینی احتمال وقوع یک رویداد باینری (بله/خیر) استفاده می شود.اصطلاح “لجستیک” از تابع logit که در این روش طبقه بندی استفاده می شود، می آید. تابع لجستیک که تابع سیگموئید نیز نامیده میشود، یک منحنی S شکل است که میتواند هر عدد با ارزش واقعی را بگیرد و بین 0 و 1 ترسیم کند، اما هرگز دقیقاً در آن محدوده نیست. . نمونه ای از رگرسیون لجستیک می تواند استفاده از یادگیری ماشینی برای تعیین اینکه آیا یک فرد احتمالاً به COVID-19 آلوده شده است یا خیر.
مثال سادهی دیگری که میتوانیم به آن اشاره کنیم این است که فرض کنید که برادر کوچک شما در حال تلاش برای ورود به دبیرستان است، و شما می خواهید پیش بینی کنید که آیا او در موسسه رویایی خود پذیرفته می شود یا خیر. بنابراین، بر اساس CGPA وی و داده های گذشته، می توانید از رگرسیون لجستیک برای پیش بینی نتیجه استفاده کنید.
Support Vector Machine
ماشین بردار پشتیبانی (SVM) یک الگوریتم یادگیری ماشینی نظارت شده است که برای طبقهبندی و رگرسیون استفاده میشود. اگرچه می گوییم مشکلات رگرسیون نیز برای طبقه بندی مناسب است. هدف از الگوریتم SVM یافتن یک ابر صفحه در یک فضای N بعدی است که به طور مشخص نقاط داده را طبقه بندی می کند. بعد هایپرپلن به تعداد ویژگی ها بستگی دارد. اگر تعداد ویژگی های ورودی دو باشد، آنگاه هایپرپلن فقط یک خط است. اگر تعداد ویژگی های ورودی سه باشد، آنگاه هایپرپلن به یک صفحه دو بعدی تبدیل می شود. تصور زمانی که تعداد ویژگی ها از 3 بیشتر شود دشوار می شود.
مزایای استفاده از الگوریتم Support Vector Machine
- در دادههایی با حجم و ابعاد بالا به طرز مؤثر کارآمد است.
- توابع کرنل مختلف را میتوان برای توابع تصمیم مشخص کرد و امکان تعیین کرنلهای سفارشی وجود دارد.
- حافظه آن کارآمد است زیرا از زیر مجموعهای از نقاط آموزشی در تابع تصمیم به نام بردارهای پشتیبانی استفاده میکند.
سخن آخر
الگوریتمهای هوش مصنوعی حوزه وسیعی است که از الگوریتمهای یادگیری ماشین و الگوریتمهای یادگیری عمیق تشکیلشده است. الگوریتمهای هوش مصنوعی به ماشینها توانایی تصمیمگیری، تشخیص الگوها و نتیجهگیری را میدهند که اساساً تقلید از هوش انسانی است. در مقاله فوق، حوزه وسیعی را برای رویکردی ازیادگیری (یادگیری تحت نظارت، بدون نظارت و تقویتی) بررسی کردیم که در آن از این الگوریتم ها برای نتیجه گیری استفاده میشود. علاوه بر این، این الگوریتمها با توجه به نوع مسائل به سه دسته طبقهبندی، رگرسیون و روشهای خوشهبندی دستهبندی میشوند. امیدوارم این مطلب برای شما مفید واقع شده باشد.