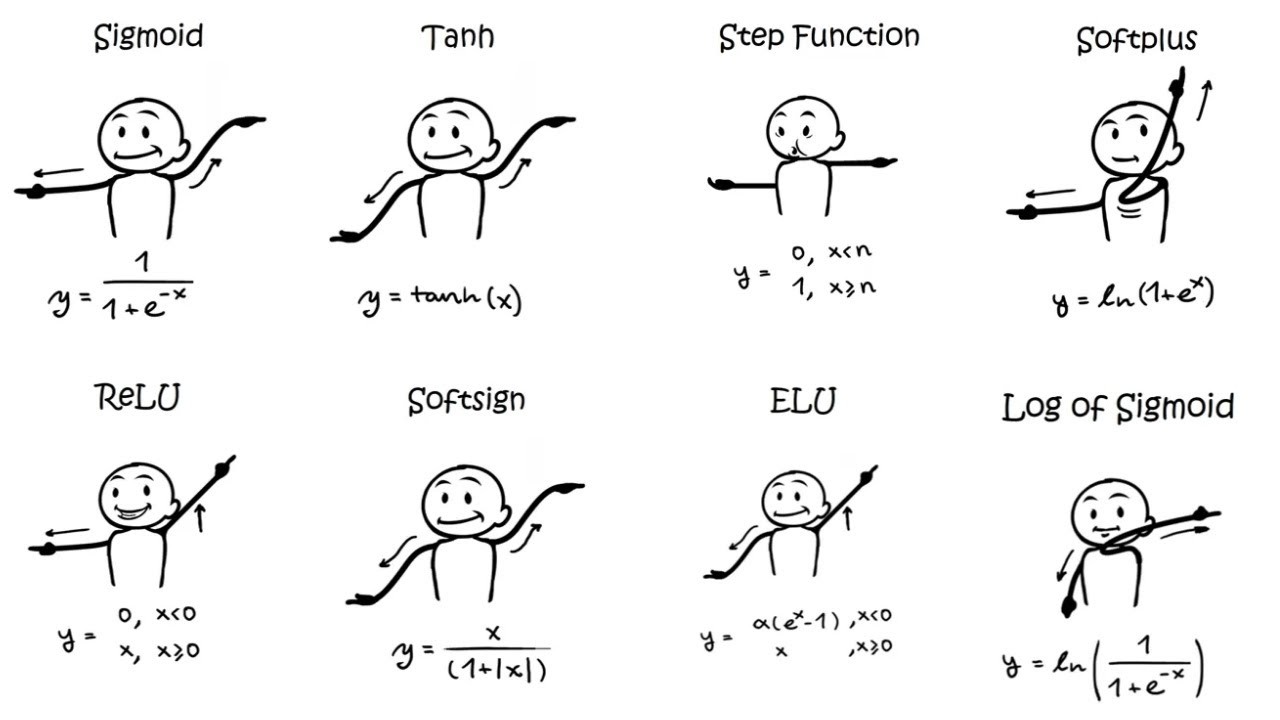
داشتن درک کامل از مفهوم و عملکرد تابع فعالسازی یکی از مهمترین مباحث در یادگیری شبکههای عصبی است. یکی از مراحل مهم در ساخت شبکهی عصبی انتخاب تابع فعالسازی مناسب است و لازمهی این کار داشتن درک کامل از انواع تابع فعالسازی و تفاوتهای آنها با یکدیگر است. در این محتوا، ما در مورد توابع فعال سازی سیگموئید و tanh صحبت خواهیم کرد. ابتدا به معرفی مختصری از هر دو تابع فعال سازی می پردازیم و همچنین در ادامه آنها را با هم مقایسه میکنیم.
مروری بر تابع فعالسازی
یکی از اجزای سازنده شبکه عصبی، تابع فعال سازی است که تصمیم میگیرد نورون فعال شود یا نه. به طور خاص، مقدار یک نورون در یک شبکه عصبی به صورت زیر محاسبه میشود:

که در آن x_i ویژگیهای ورودی، w_i وزنها، و b بایاس نورون است. سپس، تابع فعالسازی در مقدار هر نورون اعمال میشود و تصمیم میگیرد که آیا نورون فعال است یا خیر:

در شکل زیر به صورت نموداری نحوه عملکرد یک تابع فعال سازی را می بینیم:
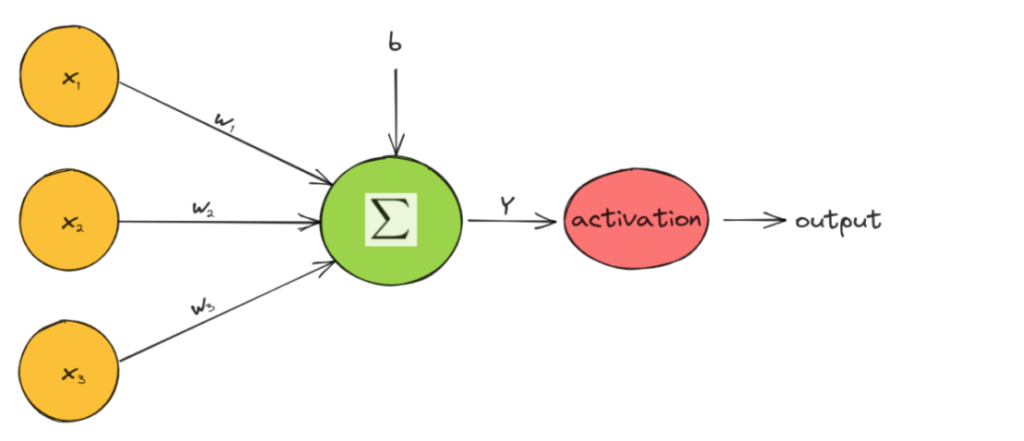
توابع فعالسازی تک متغیره و غیرخطی هستند، زیرا یک شبکه با تابع فعالسازی خطی معادل یک مدل رگرسیون خطی است. با توجه به غیر خطی بودن توابع فعال سازی، شبکههای عصبی میتوانند ساختارهای معنایی پیچیدهای را جذب کرده و به عملکرد بالایی دست یابند.
مروری بر تعریف تابع فعالسازی سیگموئید
تابع فعالسازی سیگموئید (که تابع لجستیک نیز نامیده میشود) هر مقدار واقعی را به عنوان ورودی میگیرد و مقداری در محدوده {(0, 1)} را خروجی میکند. به صورت زیر محاسبه میشود:

که در آن x مقدار خروجی نورون است. در زیر، میتوانیم نمودار تابع سیگموید را زمانی که ورودی در محدوده [-10, 10] قرار دارد، مشاهده کنیم:
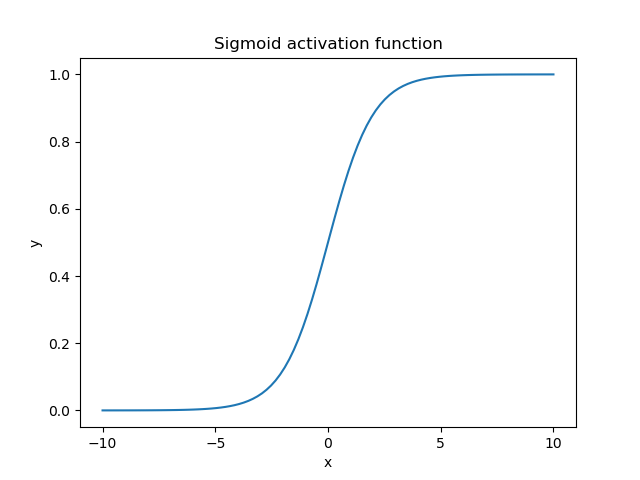
همانطور که انتظار میرود، تابع سیگموئید غیر خطی است و مقدار یک نورون را در محدوده کوچک (0، 1) محدود میکند. هنگامی که مقدار خروجی نزدیک به 1 است، نورون فعال است و جریان اطلاعات را فعال میکند، در حالی که مقدار نزدیک به 0 مربوط به یک نورون غیرفعال است.
همچنین، یک ویژگی مهم تابع سیگموید این واقعیت است که به دلیل شکل S مانند آن، تمایل دارد مقادیر ورودی را به دو انتهای منحنی (0 یا 1) فشار دهد. در ناحیه نزدیک به صفر، اگر مقدار ورودی را کمی تغییر دهیم، تغییرات مربوطه در خروجی بسیار زیاد است و بالعکس. برای ورودیهای کمتر از 5- خروجی تابع تقریبا صفر است در حالی که برای ورودیهای بزرگتر از 5 خروجی تقریبا یک است.
در نهایت، خروجی تابع فعال سازی سیگموید را میتوان به عنوان یک احتمال تفسیر کرد زیرا در محدوده [0، 1] قرار دارد. به همین دلیل است که در نورونهای خروجی یک کار پیشبینی نیز استفاده میشود.
تابع هذلولی مماس یا Tanh
تابع فعال سازی دیگری که در یادگیری عمیق رایج است تابع هذلولی مماس است که به سادگی به عنوان تابع tanh شناخته میشود. به صورت زیر محاسبه می شود:
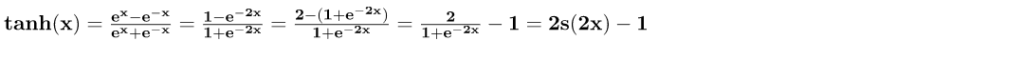
مشاهده میکنیم که تابع tanh یک نسخه جابهجا شده و کشیده از سیگموید است. در زیر، میتوانیم نمودار آن را زمانی که ورودی در محدوده [-10, 10] قرار دارد، مشاهده کنیم:
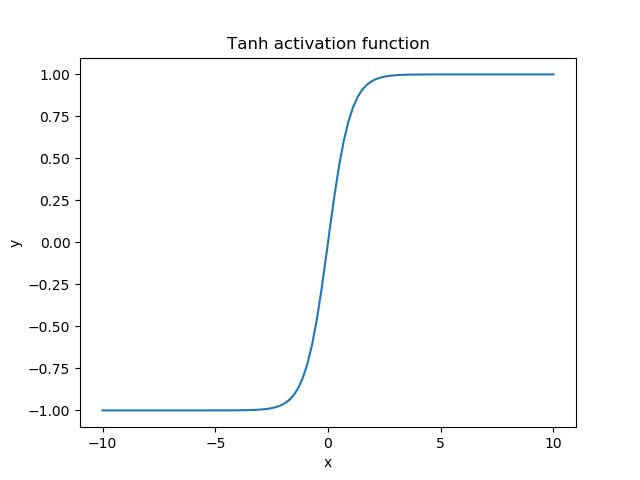
محدوده خروجی تابع tanh (-1، 1) است و رفتاری مشابه با تابع سیگموید نشان میدهد. تفاوت اصلی در این واقعیت است که تابع tanh مقادیر ورودی را به جای 1 و 0 به 1 و -1 فشار میدهد.
شباهتهای دو تابع فعالسازی Sigmoid vs Tanh
همانطور که قبلاً اشاره کردیم، تابع tanh یک نسخه کشیده و جابهجا شده از تابع فعالسازی سیگموید است. بنابراین، شباهتهای زیادی بین این دو وجود دارد.
هر دو تابع متعلق به توابع S مانند هستند که مقدار ورودی را به یک محدوده محدود سرکوب میکنند. این به شبکه کمک میکند تا وزنهای خود را محدود نگه دارد و از مشکل گرادیان انفجاری که در آن مقدار گرادیانها بسیار بزرگ میشود جلوگیری میکند.
آیا تابع سیگموئید لجستیک فقط یک نسخه تغییر مقیاس شده از تابع تانژانت هایبرپلیک (tanh) است؟
پاسخ کوتاه بله است!
توابع مماس هذلولی (tanh) و سیگموید لجستیک (Sigmoid) به صورت زیر تعریف میشوند:
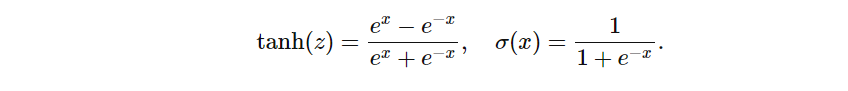
و اگر این توابع را در کنار هم ترسیم کنیم، این رابطه تقریباً با چشم قابل تشخیص است:
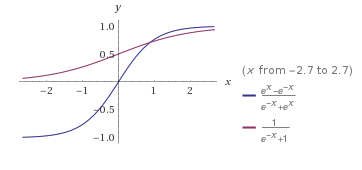
از آنجایی که تابع سیگموید لجستیک حول مبدا متقارن است و مقداری در محدوده [0، 1] برمیگرداند، می توانیم رابطه زیر را بنویسیم.
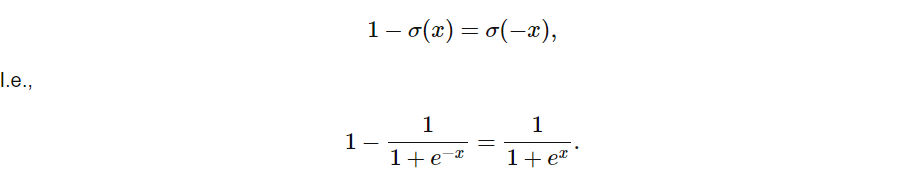
اکنون، برای مشاهده رابطه بین tanh و Sigmoid، اجازه دهید تابع tanh را به شکلی مشابه به این صورت بازآرایی کنیم:
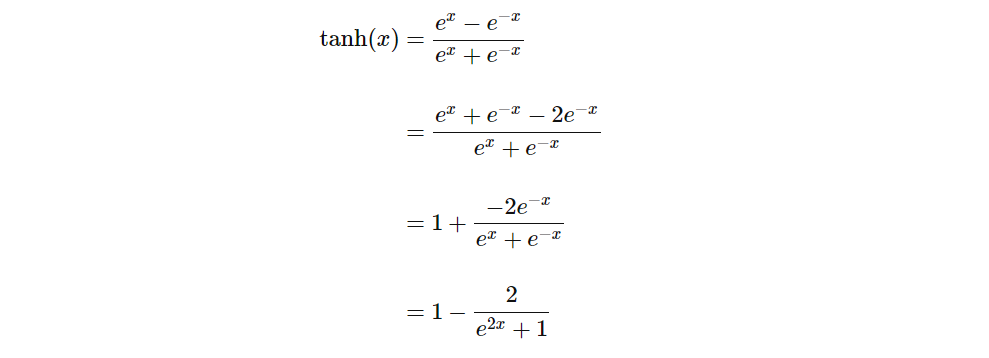
اکنون، از دیدگاه سیگموئید لجستیک، ما داریم:
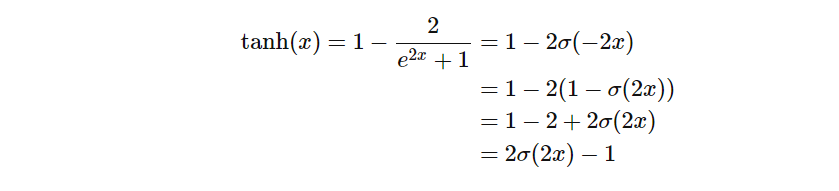
تفاوتهای دو تابع فعالسازی Sigmoid vs Tanh
یک تفاوت مهم بین این دو تابع، رفتار گرادیان آنها است. بیایید گرادیان هر تابع فعال سازی را محاسبه کنیم:

در زیر، گرادیان تابع فعال سازی سیگموئید (قرمز) و tanh (آبی) را رسم می کنیم:
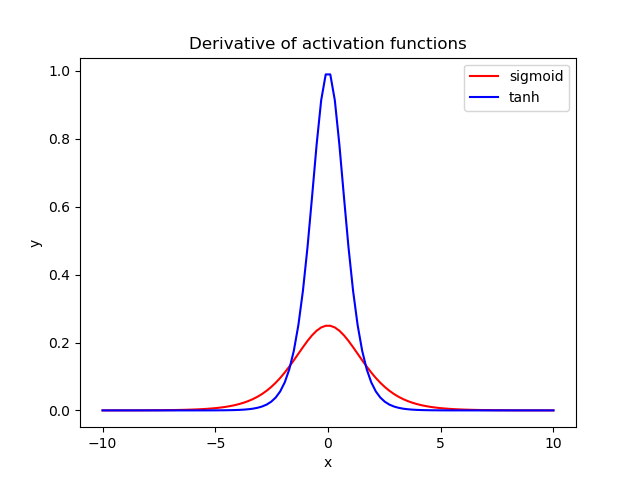
هنگامی که ما از این توابع فعال سازی در یک شبکه عصبی استفاده میکنیم، دادههای ما معمولاً حول محور صفر هستند. بنابراین، ما باید توجه خود را بر روی رفتار هر گرادیان در منطقه نزدیک به صفر متمرکز کنیم. مشاهده میکنیم که گرادیان tanh چهار برابر بیشتر از گرادیان تابع سیگموید است. این بدان معنی است که استفاده از تابع فعال سازی tanh منجر به مقادیر بیشتر گرادیان در طول تمرین و به روزرسانی بیشتر در وزنهای شبکه میشود. بنابراین، اگر شیبهای قوی و مراحل یادگیری بزرگ میخواهیم، باید از تابع فعال سازی tanh استفاده کنیم. تفاوت دیگر این است که خروجی tanh متقارن در اطراف صفر است که منجر به همگرایی سریعتر میشود.
ناپدید شدن گرادیان
با وجود مزایایی که دارند، هر دو تابع به اصطلاح مشکل گرادیان ناپدید شدن را له همراه خود دارند.
در شبکههای عصبی، خطا از طریق لایههای پنهان شبکه منتشر میشود و وزنها را به روز میکند. در صورتی که یک شبکه عصبی بسیار عمیق و توابع فعال سازی محدود مانند موارد بالا داشته باشیم، پس از انتشار مجدد آن در هر لایه پنهان، میزان خطا به طور چشمگیری کاهش مییابد. بنابراین، در لایههای اولیه، خطا تقریباً صفر است و وزن این لایهها به درستی بهروز نمیشود. تابع فعال سازی ReLU میتواند مشکل گرادیان ناپدید شدن را برطرف کند.
مثالی در حوزهی ناپدید شدن گرادیان:
در نهایت، نمونهای از اعمال این توابع فعالسازی را در یک نورون ساده از دو ویژگی ورودی x_1 = 0.1، x_2 = 0.4 و وزنهای w_1 = 0.5، w_2 = 0.5 ارائه میکنیم. در زیر، هنگام استفاده از تابع فعالسازی سیگموئید (چپ) و tanh (راست) میتوانیم مقدار خروجی و گرادیان را ببینیم:
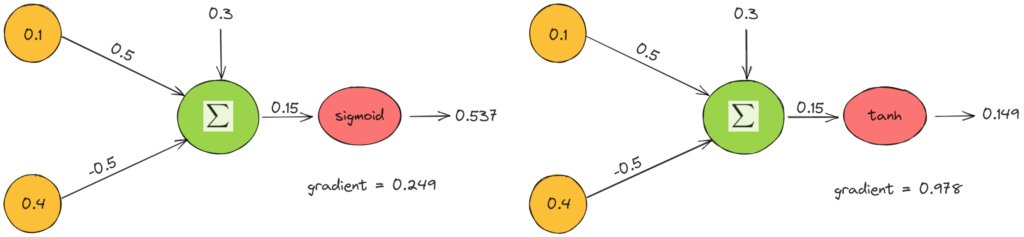
مثال بالا نظرات قبلی ما را تأیید می کند. مقدار خروجی tanh نزدیک به صفر است و گرادیان چهار برابر بیشتر است.
سخن آخر
در این آموزش در مورد دو تابع فعال سازی tanh و sigmoid صحبت کردیم. ابتدا مروری بر هرمفاهیم هر کدام داشتیم و سپس دو تابع را همراه با یک مثال شرح و مقایسه کردیم. اگر مشتاق هستید دربارهی توابع فعالسازی بیشتر یاد بگیرید حتماً به سری آموزشهای توابع فعال سازی پرتال هوش مصنوعی سر بزنید.

