یادگیری ماشین همانطور که از نامش پیداست در مورد یادگیری خودکار ماشینها بدون برنامهریزی صریح یا به زیان دیگر یادگیری کامپیوتر بدون دخالت مستقیم انسان است. فرآیند یادگیری ماشینی با ورود دادههای با کیفیت و قابل استناد سپس آموزش ماشینها با ساخت مدلهای مختلف یادگیری ماشین با استفاده از دیتاهای ورودی و الگوریتمهای مختلف شروع میشود. انتخاب الگوریتمها در این فرآیند بستگی به نوع دادههای ما و اینکه ماشین چه وظایفی بر عهده دارد صورت میگیرد.
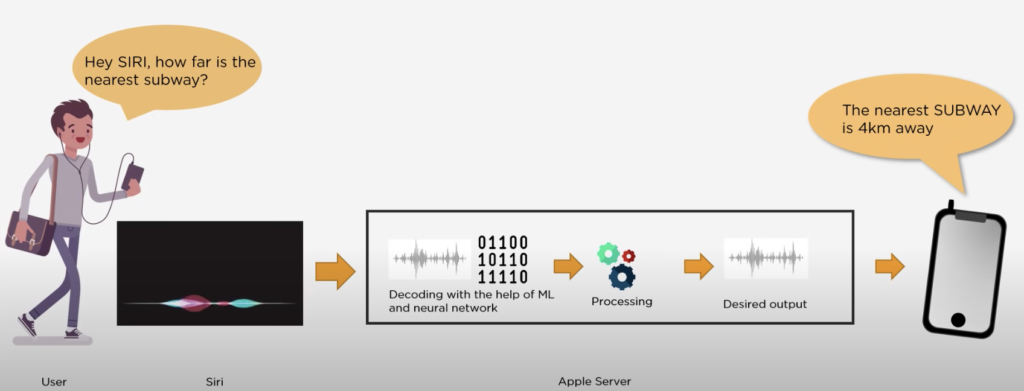
هر بار که ما از اپلیکیشن سیری (Siri) سؤالی میپرسیم، الگوریتمهای تشخیص گفتار و کلام هوش مصنوعی دستگاه ما فعال میشود، اطلاعات را پردازش میکند و به کدهای قابل اجرا تبدیل میکند. یادگیری ماشین پروسهای برای قادر کردن کامپیوترها و ماشینها به دریافت اطلاعات، پردازش آنها در نهایت رفتار و پاسخ همانند انسانها میباشد.
یادگیری ماشینی، در ساده ترین عبارت، آموزش دادن به ماشین شما در مورد چیزی است. یادگیری ماشینی فرآیند ایجاد مدلهایی است که میتوانند کار خاصی را بدون نیاز به برنامهریزی صریح انسان برای انجام کاری انجام دهند. در این مطلب به بررسی یادگیری ماشین نظارت شده میپردازیم.
فهرست مطالب
یادگیری ماشین نظارت شده (Supervised Machine learning) چیست؟
عملکرد یادگیری ماشین تحت نظارت
مزایای یادگیری ماشین تحت نظارت
چالشهای یادگیری تحت نظارت (Supervised learning)
یادگیری ماشین نظارت شده (Supervised Machine learning) چیست؟
یادگیری نظارت شده انواعی از یادگیری ماشینی است که در آن ماشینها با استفاده از دادههای آموزشی «برچسبگذاریشده» آموزش داده میشوند و بر اساس آن دادهها، ماشینها خروجی را پیشبینی میکنند. دادههای برچسب زده شده به این معنی است که برخی از دادههای ورودی قبلاً با خروجیای که خواهند داد، برچسب گذاری شدهاند.هدف الگوریتم یادگیری نظارت شده، یافتن یک تابع برای ترسیم متغیر ورودی (x) با متغیر خروجی (y) است. در یادگیری نظارت شده، هر مثال یک جفت شی ورودی و یک مقدار خروجی مورد نیاز است. مدل یادگیری نظارت شده تا زمانی آموزش داده میشود که بتواند روابط و الگوهای اساسی بین برچسب دادههای ورودی و خروجی را تشخیص دهد و به آن اجازه میدهد هر زمان که مجموعه جدیدی از دادهها ارائه میشود برچسب گذاری دقیق ارائه و تشخیص دهد. الگوریتم یادگیری نظارت شده، دادههای آموزشی را تجزیه و تحلیل میکند و یک تابع ضمنی ارائه میدهد که میتواند برای ترسیم نمونههای جدید استفاده شود. با یادگیری نظارت شده، یک سازمان میتواند مشکلات مختلفی از جمله طبقهبندی نامههای Spam، طبقه بندی تصاویر، تشخیص تقلب و ارزیابی ریسک را حل کند.
مراحل یادگیری نظارت نشده
مراحل مربوط به یادگیری تحت نظارت به شرح زیر است:
ابتدا نوع مجموعه داده آموزشی را تعیین کنید
دادههای آموزشی برچسب گذاری شده را جمع آوری / تعیین کنید.
مجموعه اطلاعات برچسبگذاری شده را به، مجموعه داده آزمایشی و مجموعه داده اعتبار سنجی تقسیم کنید.
ویژگیهای ورودی مجموعه داده آموزشی را تعیین کنید، که باید دانش کافی داشته باشد تا مدل بتواند خروجی را به طور دقیق پیشبینی کند.
الگوریتم مناسب برای مدل مانند ماشین بردار پشتیبان، درخت تصمیم و… را تعیین کنید.
الگوریتم را روی مجموعه داده آموزشی اجرا کنید. گاهی اوقات ما به مجموعه های اعتبارسنجی به عنوان پارامترهای کنترلی نیاز داریم که زیرمجموعه مجموعه دادههای آموزشی هستند.
با ارائه مجموعه تست، دقت مدل را ارزیابی کنید. اگر مدل خروجی صحیح را پیشبینی کند، به این معنی است که مدل ما دقیق است.
مثالی از یادگیری نظارت شده:
با ایجاد مجموعهای از دادههای طبقهبندی شده شروع کنید. این دسته از دیتا شامل:
شرایط آب و هوایی
زمان و ساعات خاص در روز
تعطیلات
اینها جزئیات ورودیهای دستهبندی شده شما در این مثال آموزشی تحت نظارت هستند. خروجی مقدار زمانی است که برای بازگشت به خانه در آن روز خاص طول میکشید. شما به طور غریزی میدانید که اگر بیرون باران ببارد، رانندگی به خانه طولانیتر خواهد بود. اما ماشین برای پیشبینی این مدت زمان به دادهها و آمار نیاز دارد.
بیایید چند نمونه یادگیری تحت نظارت را ببینیم که چگونه میتوانید یک مدل یادگیری نظارت شده از این مثال ایجاد کنید که به کاربر در تعیین زمان رفت و آمد کمک میکند. اولین چیزی که برای ایجاد آن نیاز دارید یک مجموعه آموزشی است. این مجموعه آموزشی شامل کل زمان رفت و آمد و عوامل مربوطه مانند آب و هوا، زمان و… است. بر اساس این مجموعه آموزشی، ممکن است دستگاه شما ببیند که رابطه مستقیمی بین میزان بارندگی و زمانی که برای رسیدن به خانه باید طی کنید، وجود دارد.
بنابراین، مشخص میکند که هر چه باران بیشتر باشد، مدت زمان بیشتری برای بازگشت به خانه خود رانندگی خواهید کرد. همچنین ممکن است ارتباط بین زمانی که کار را ترک میکنید و زمانی که در راه هستید را پیشبینی کند.
هر چه به ساعت 6 بعدازظهر نزدیک میشوید. بیشتر طول میکشد تا شما به خانه برگردید. ممکن است دستگاه شما برخی از روابط را با دادههای برچسب گذاری شده شما پیدا کند این شروع ساخت مدلی از دادههای شما است.
عملکرد یادگیری ماشین تحت نظارت
در یادگیری نظارت شده، مدلها با استفاده از مجموعه دادههای برچسبگذاری شده آموزش داده میشوند، جایی که مدل در مورد هر نوع داده میآموزد. پس از تکمیل فرآیند آموزش، مدل بر اساس دادههای آزمون (زیرمجموعه ای از مجموعه آموزشی) آزمایش میشود و سپس خروجی را پیش بینی میکند.
عملکرد یادگیری تحت نظارت را میتوان به راحتی با مثال و نمودار زیر درک کرد:
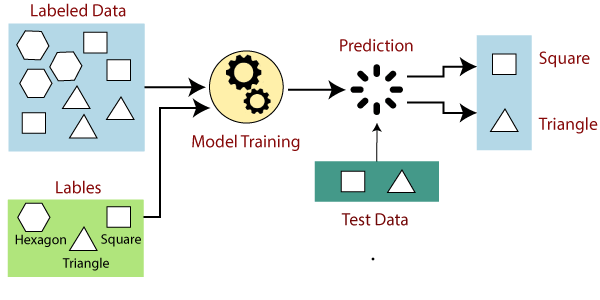
فرض کنید مجموعه دادهای از انواع مختلف اشکال داریم که شامل مربع، مستطیل، مثلث و چند ضلعی است. اکنون اولین قدم این است که باید مدل را برای هر شکل آموزش دهیم.
اگر شکل داده شده چهار ضلع داشته باشد و همه اضلاع آن برابر باشند، آن را به عنوان مربع مشخص میکنیم.
اگر شکل داده شده سه ضلع داشته باشد، به عنوان یک مثلث علامت گذاری میشود.
اگر شکل داده شده دارای شش ضلع مساوی باشد، به عنوان شش ضلعی علامت گذاری میشود.
حالا بعد از آموزش مدل خود را با استفاده از مجموعه تست تست میکنیم و وظیفه مدل شناسایی شکل است.
این دستگاه قبلاً روی انواع شکلها آموزش دیده است و وقتی شکل جدیدی پیدا کرد، شکل را بر اساس تعدادی اضلاع طبقه بندی میکند و خروجی را پیشبینی میکند.
اهمیت یادگیری ماشین نظارت شده
اهمیت یادگیری ماشینی در توانایی آن برای تبدیل دادهها به بینش و پیشبینی نتایج اطلاعات ورودی است. این به کسبوکارها اجازه میدهد تا از دادهها برای درک بهتر و اجتناب از یک نتیجه ناخواسته یا افزایش نتیجه دلخواه یک متغیر هدف استفاده کنند.
کاربردهای یادگیری ماشین نظارت شده در زندگی روزمره
۱ـ رگرسیون: این الگوریتم برای هر مثال یک هدف عددی تولید میکند، به عنوان مثال، چقدر درآمد از یک کمپین بازاریابی جدید ایجاد میشود.
۲ـ طبقه بندی: الگوریتم هر نمونه را با تصمیم گیری بین دو یا چند کلاس مختلف برچسب گذاری میکند. تصمیم گیری بین دوطبقه بندی باینری نامیده میشود، به عنوان مثال، پیشبینی اینکه آیا یک شخص در پرداخت وام تأخیر میکند یا خیر. هنگامی که تصمیمی بین بیش از دو کلاس گرفته میشود، به عنوان طبقه بندی چند طبقه شناخته میشود.
مزایای یادگیری ماشین تحت نظارت
۱ـ با یادگیری نظارت شده، میتوانید به راحتی دادهها را جمع آوری کنید یا یک خروجی داده از تجربه قبلی ایجاد کنید.
۲ـ یادگیری تحت نظارت به حل آسان مسائل محاسباتی در دنیای واقعی کمک می کند.
۳ـ با استفاده از تجربه، یادگیری تحت نظارت میتواند معیارهای عملکرد را نیز بهینه کند.
معایب یادگیری ماشین تحت نظارت
۱ـ مدلهای یادگیری تحت نظارت برای انجام وظایف پیچیده مناسب نیستند.
۲ـاگر دادههای آزمون با مجموعه داده آموزشی متفاوت باشد، یادگیری تحت نظارت نمی تواند خروجی صحیح را پیش بینی کند.
۳ـآموزش به زمان های محاسباتی زیادی نیاز داشت.
۴ـدر یادگیری نظارت شده، ما به دانش کافی در مورد طبقات شی نیاز داریم.
چالشهای یادگیری تحت نظارت (Supervised learning)
۱ـ تداخل دادههای آموزشی با ویژگیهای ورودی نامربوط میتواند منجر به نتایج نادرست شود.
۲ـ آماده سازی و پیش پردازش دادهها همیشه چالش برانگیز است.
۳ـ اگر متخصصی برای آموزش مدل یادگیری ماشین ندارید، میتوانید از روش «بروت فورس» نیز استفاده کنید. این روش به معنای انتخاب ویژگیهای مناسب (متغیرهای ورودی) برای آموزش سیستم است. با این حال، ممکن است نادرست باشد.
۴ـهنگامی که مقادیر غیرممکن، بعید یا ناقص به عنوان دادههای آموزشی استفاده میشود، دقت مدل کاهش مییابد.
الگوریتمهای یادگیری ماشین تحت نظارت
همانطور که در بخش قبل ذکر شد، یادگیری ماشین نظارت شده دارای چندین الگوریتم است که برای فرآیندهای یادگیری ماشین نظارت شده استفاده میشود. در این قسمت توضیحاتی در مورد متداول ترین موارد استفاده میشود تا به شما در درک نحوه عملکرد این الگوریتمها کمک کند.
رگرسیون خطی:
از رگرسیون خطی برای تعیین رابطه بین متغیرهای مستقل و وابسته برای پیش بینی نتایج احتمالی در آینده استفاده میشود. زمانی که تعداد متغیرهای مستقل و وابسته یک باشد به آن رگرسیون خطی ساده می گویند. اما با افزایش تعداد متغیرها به آن رگرسیون خطی چندگانه می گویند. خطی که نشاندهنده رابطه بین دو متغیر (مثبت یا منفی) در یک نمودار است، خط رگرسیون نامیده می شود. و برای هر رگرسیون خطی، به دنبال نمودار خطی با بهترین برازش است که از طریق روشهای حداقل مربعات محاسبه میشود.
رگرسیون لجستیک:
برخلاف رگرسیون خطی که برای مقادیر وابسته پیوسته استفاده میشود، رگرسیون لجستیک زمانی انتخاب میشود که متغیر وابسته مقولهای باشد، یعنی «بله» یا «خیر» و «درست» یا «نادرست». رگرسیون لجستیک عمدتاً برای حل مشکلات طبقه بندی باینری مانند شناسایی هرزنامه استفاده می شود.
K-نزدیکترین همسایه:
K-Nearest Neighbor یا K-NN ساده ترین الگوریتمی است که در یادگیری نظارت شده استفاده میشود. این یک الگوریتم ناپارامتریک است (یعنی پیشفرضهایی در مورد دادههای اساسی ایجاد نمیکند) که نقاط داده را بر اساس ارتباط و نزدیکی به سایر دادههای موجود دستهبندی میکند. الگوریتم K-NN فقط داده ها را در مرحله آموزش ذخیره می کند و فقط در زمان طبقه بندی، عمل می کند و آن داده ها را در دسته بندی دقیق طبقه بندی می کند. از این رو، نام دیگر آن: الگوریتم یادگیرنده تنبل است. الگوریتم KNN عمدتا برای تشخیص تصویر و موتور توصیه استفاده میشود.
جنگل تصادفی:
جنگل تصادفی یک الگوریتم انعطاف پذیر از یادگیری نظارت شده است که برای مسائل طبقه بندی و رگرسیون استفاده میشود. کلمه “جنگل” در جنگل تصادفی به مجموعهای از درخت های تصمیم گیری نامرتبط اشاره دارد که برای کاهش واریانس و ایجاد پیشبینیهای بسیار دقیق دادهها ادغام شدهاند. دقت مجموعه دادههای بزرگ را کنترل میکند و مقادیر گمشده را حفظ میکند. الگوریتم جنگل تصادفی میتواند برای طبقه بندی متقاضی وام وفادار، پیش بینی بیماری ها و شناسایی فعالیت های متقلبانه استفاده شود.
ماشینهای بردار پشتیبانی:
الگوریتم دیگری که برای مسائل رگرسیون و طبقهبندی استفاده میشود، ماشینهای بردار پشتیبانی (SVM) است. هدف SVM ایجاد بهترین خط یا مرز تصمیم برای تفکیک فضای n بعدی به کلاسها است. بنابراین، ما می توانیم نقاط داده جدید را در دسته بندی مناسب قرار دهیم. و این بهترین خط یا مرز تصمیم به عنوان یک ابر صفحه شناخته میشود که کلاسهای نقاط داده را در دو طرف صفحه در حداکثر آن جدا می کند. میتوان از آن برای دسته بندی متن، تشخیص چهره و طبقه بندی تصاویر استفاده کرد.
سخن آخر
با استفاده از مدلهای یادگیری نظارت شده، طبقهبندی دستی دادهها در برنامه شما حذف میشود و پیشبینیهایی براساس دادههای برچسبگذاری شده انجام میشود. اما آموزش و استفاده از یادگیری ماشینی تحت نظارت برای هر پروژهای نیازمند دانش و تخصص انسانی است. و با دانش اولیه کار، الگوریتمها، چالشها و مزایای آن، می توانید به راحتی تصمیم بگیرید که آیا میخواهید از یادگیری نظارت شده استفاده کنید یا خیر. امیدوارم این مطلب برای شما مفید بوده باشد.