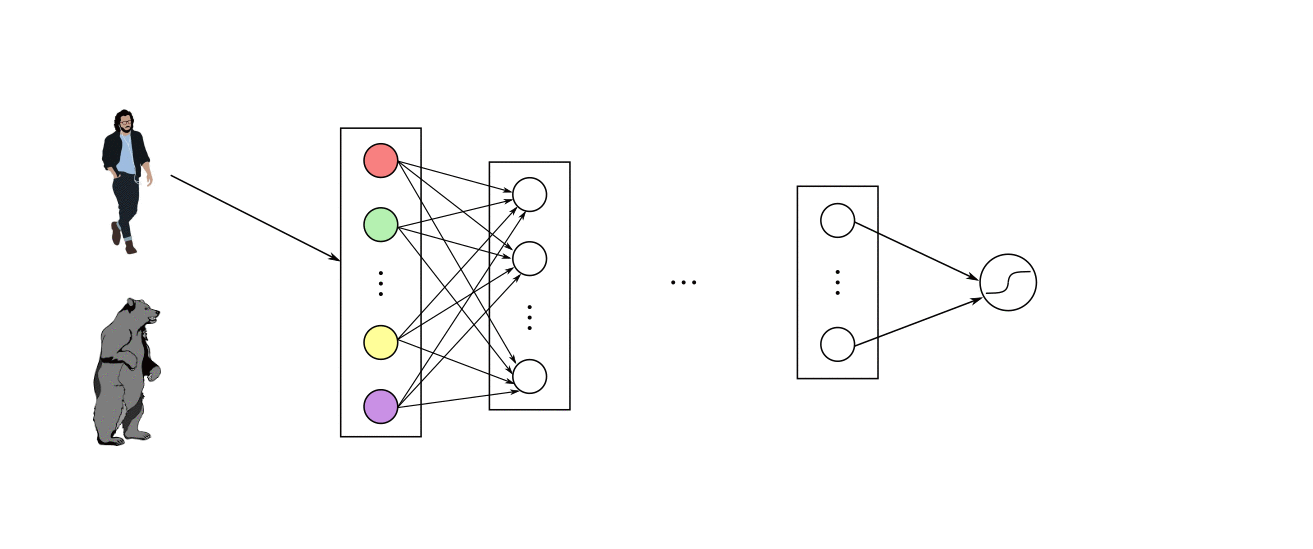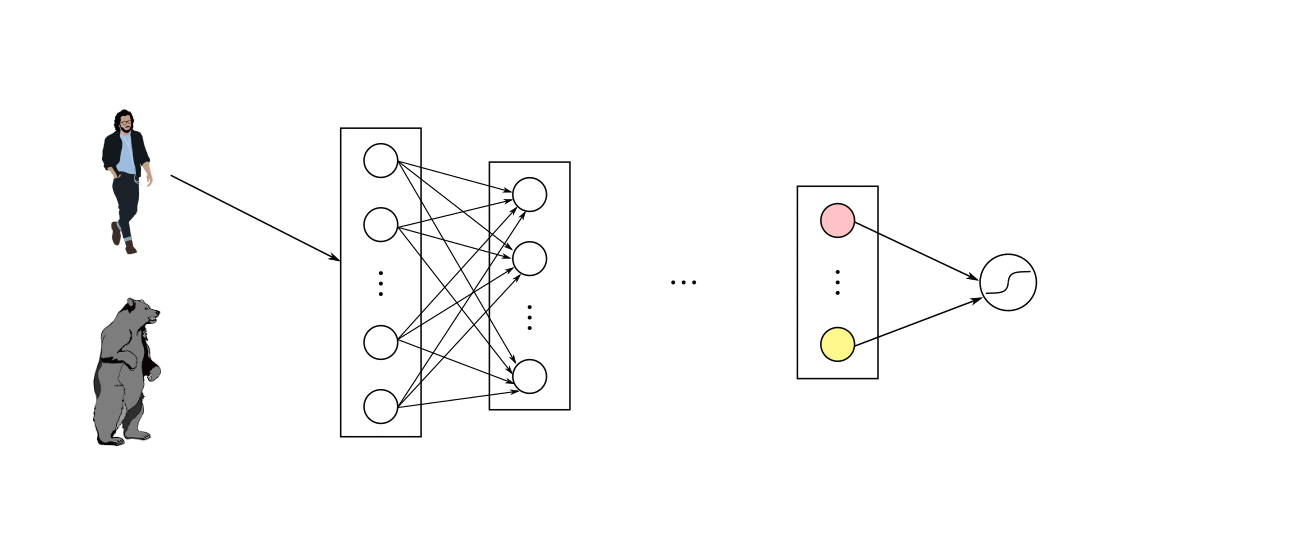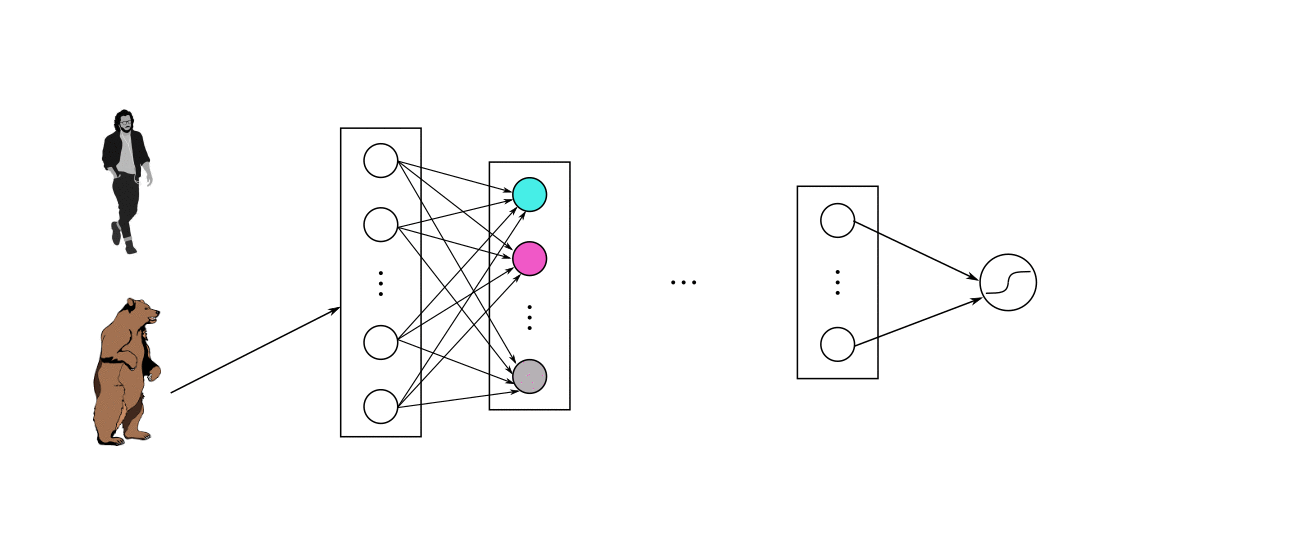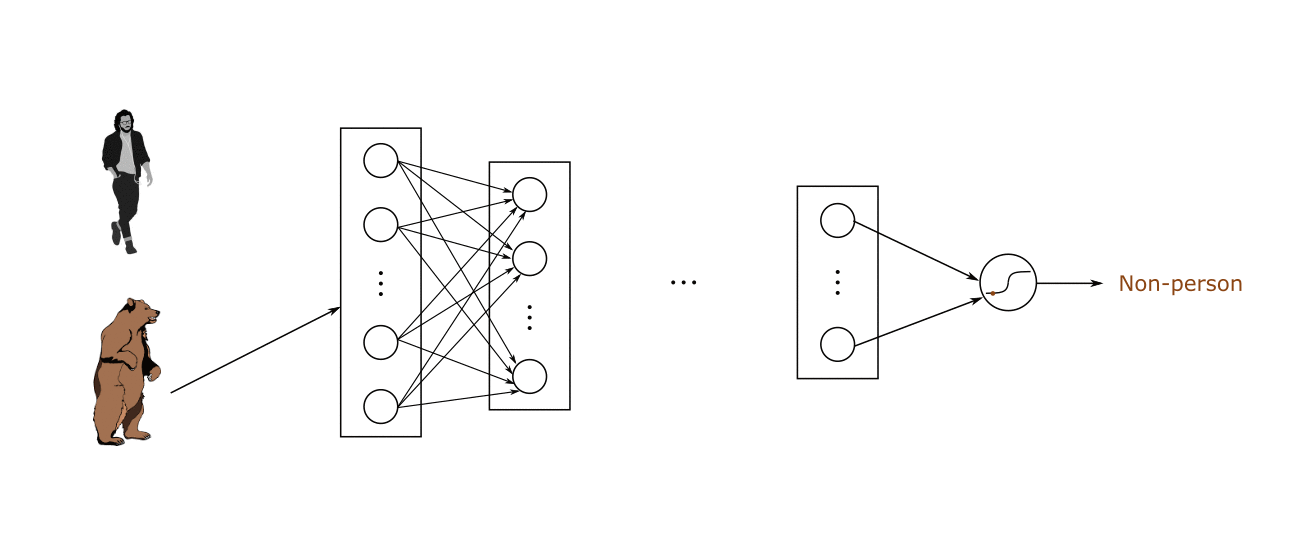
توابع فعال سازی بخش مهمی از طراحی یک شبکه عصبی هستند. همانطور که در مطالب قبل یاد گرفتیم: انتخاب تابع فعالسازی در لایه پنهان، چگونگی یادگیری مجموعه دادههای آموزشی توسط مدل شبکه را کنترل میکند. انتخاب تابع فعال سازی در لایه خروجی، نوع پیش بینی هایی را که مدل می تواند انجام دهد، مشخص می کند. به این ترتیب، برای هر پروژه شبکه عصبی یادگیری عمیق باید یک انتخاب دقیق تابع فعال سازی انجام شود. در این مطلب نحوهی انتخاب توابع فعال سازی برای مدلهای شبکه عصبی را خواهید آموخت.

آنچه دربارهی انتخاب تابع فعالسازی خواهید آموخت:
مروری بر ماهیت و ساختار تابع فعالسازی در یک شبکهی عصبی
تابع فعالسازی در لایهی پنهان
تابع فعال سازی لایه پنهان سیگموئید
تابع فعال سازی خطی اصلاح شده در لایه پنهان
تابع فعال سازی Tanh لایه پنهان
نحوه انتخاب تابع فعال سازی لایه پنهان
عملکرد فعال سازی خروجی Softmax
نحوه انتخاب یک تابع فعال سازی خروجی
مروری بر ماهیت و ساختار تابع فعالسازی در یک شبکهی عصبی
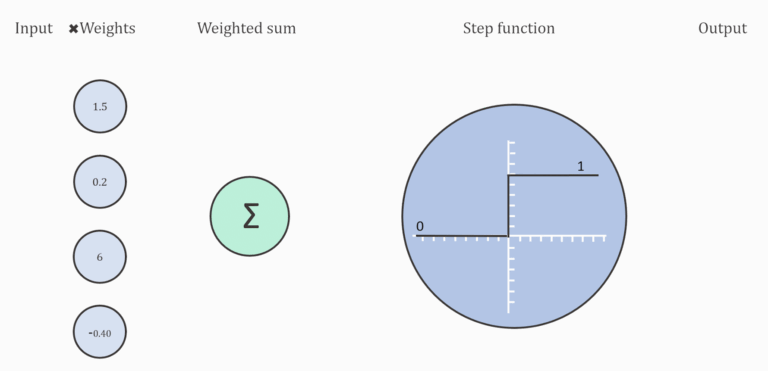
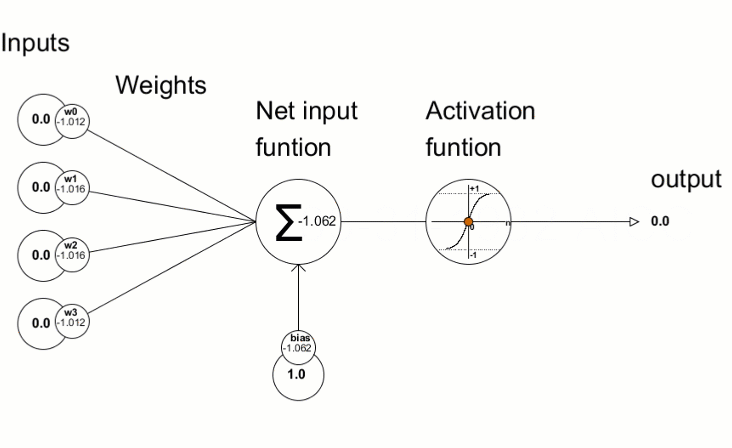
یک تابع فعال سازی در یک شبکه عصبی نحوهی تبدیل مجموعهای از دادههای ورودی به خروجی از یک گره یا گرههای یک لایه از شبکه را تعریف میکند. گاهی اوقات تابع فعال سازی “تابع انتقال” و یا “transfer function” نامیده میشود. اگر محدودهي خروجی تابع فعالسازی محدود باشد، میتوان آن را «تابع له کردن» و یا “squashing function” نامید. بسیاری از توابع فعال سازی غیرخطی هستند و ممکن است به عنوان “غیرخطی یا nonlinearity” در لایه یا طراحی شبکه شناخته شوند. انتخاب تابع فعالسازی تأثیر زیادی بر قابلیت و عملکرد شبکه عصبی دارد و از توابع فعالسازی مختلف در لایههای متفاوت استفاده میشود. از نظر فنی، تابع فعالسازی در داخل یا بعد از پردازش داخلی هر گره در شبکه استفاده میشود، اگرچه شبکهها طوری طراحی شدهاند که از یک تابع فعالسازی برای همه گرهها در یک لایه استفاده کنند.
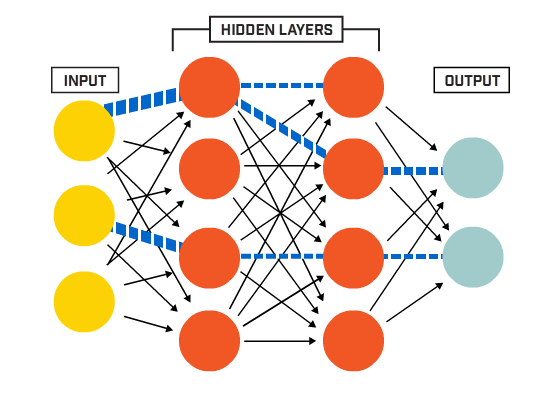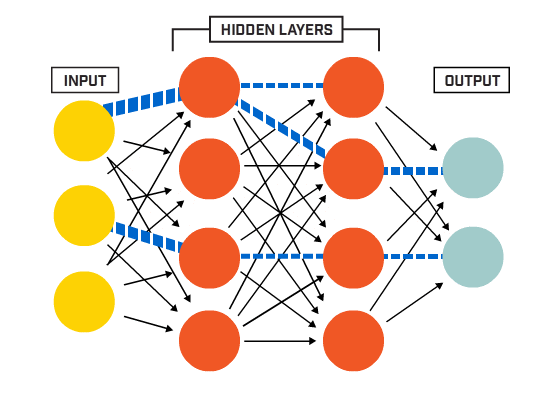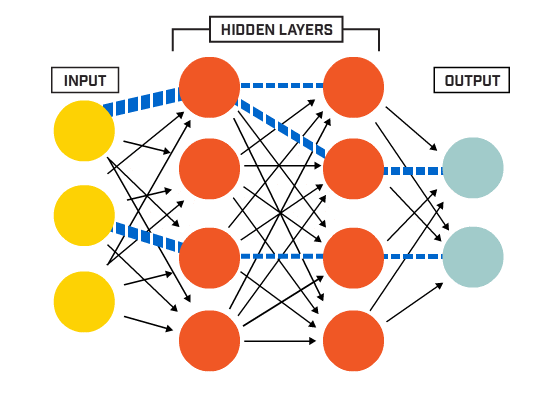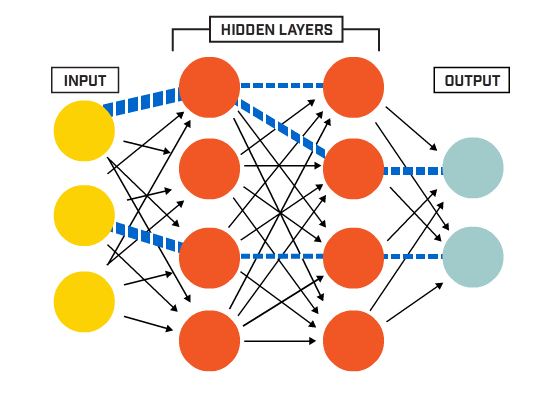
یک شبکه ممکن است سه نوع لایه داشته باشد: لایههای ورودی که دادههای اولیه را از دامنه میگیرند، لایههای مخفی که اطلاعات را از لایه دیگری میگیرند و خروجی را به لایه دیگر منتقل میکنند و لایههای خروجی که نتیجه را پیشبینی میکنند. همه لایه های پنهان معمولاً از یک تابع فعال سازی استفاده می کنند. لایه خروجی معمولاً از یک تابع فعال سازی متفاوت از لایه های پنهان استفاده می کند و به نوع پیش بینی مورد نیاز مدل بستگی دارد. توابع فعال سازی نیز معمولاً قابل تفکیک هستند، به این معنی که مشتق مرتبه اول را میتوان برای یک مقدار ورودی معین محاسبه کرد. با توجه به اینکه شبکههای عصبی معمولاً با استفاده از الگوریتم پس انتشار خطا که به مشتق خطای پیشبینی برای بهروزرسانی وزنهای مدل نیاز دارد، آموزش داده میشوند. انواع مختلفی از توابع فعالسازی در شبکههای عصبی مورد استفاده قرار میگیرند، اگرچه شاید تنها تعداد کمی از توابع در عمل برای لایههای مخفی و خروجی استفاده شوند.
بیایید نگاهی به توابع فعال سازی مورد استفاده برای هر نوع لایه بیندازیم.
تابع فعالسازی در لایهی پنهان
یک لایه پنهان در یک شبکه عصبی، لایه ای است که ورودی را از یک لایه دیگر (مانند یک لایه پنهان دیگر یا یک لایه ورودی) دریافت می کند و خروجی را برای لایه دیگر (مانند یک لایه مخفی دیگر یا یک لایه خروجی) فراهم می کند. یک لایه پنهان به طور مستقیم با داده های ورودی تماس نمی گیرد یا خروجی هایی برای یک مدل تولید نمی کند، حداقل به طور کلی. یک شبکه عصبی ممکن است دارای لایه های مخفی صفر یا بیشتر باشد. به طور معمول، یک تابع فعال سازی غیرخطی قابل تمایز در لایه های پنهان یک شبکه عصبی استفاده می شود. این به مدل اجازه می دهد تا توابع پیچیده تری را نسبت به شبکه ای که با استفاده از یک تابع فعال سازی خطی آموزش دیده است، یاد بگیرد.
شاید بخواهید سه تابع فعال سازی را برای استفاده در لایه های مخفی در نظر بگیرید. آن ها هستند:
فعالسازی خطی اصلاح شده (ReLU)
لجستیک (سیگموئید)
مماس هایپربولیک (Tanh)
این لیست کاملی از توابع فعال سازی مورد استفاده برای لایه های مخفی نیست، اما آنها بیشترین استفاده را دارند. در ادامه به بررسی دقیقتر این توابع فعالسازی و کاربرد آن میپردازیم.
تابع فعال سازی لایه پنهان سیگموئید
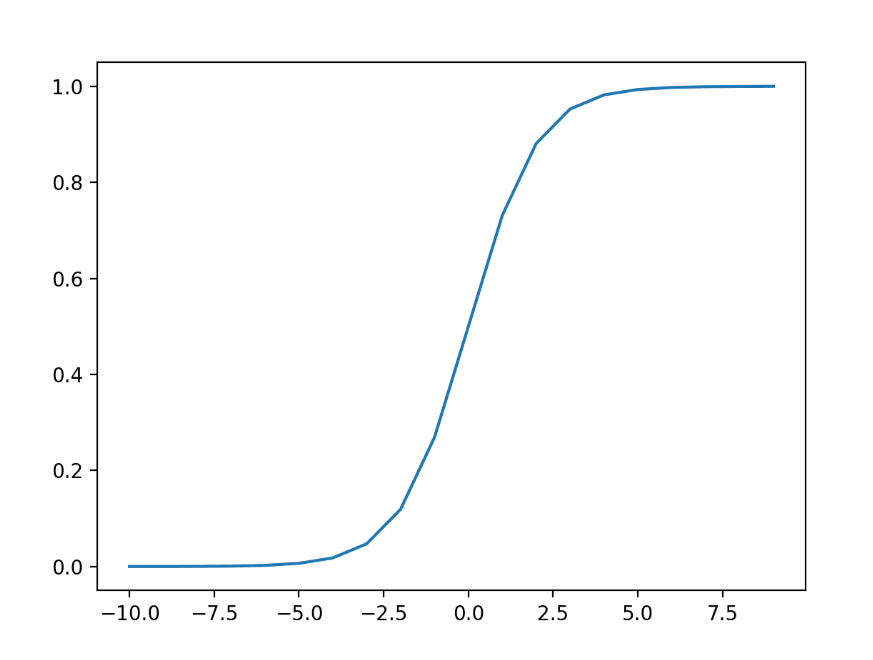
تابع فعال سازی سیگموئید را تابع لجستیک نیز می نامند. این همان تابعی است که در الگوریتم طبقه بندی رگرسیون لجستیک استفاده می شود. تابع هر مقدار واقعی را به عنوان ورودی می گیرد و مقادیری را در بازه 0 تا 1 به دست می آورد. خروجی 0.0 خواهد بود. تابع فعال سازی سیگموئید به صورت زیر محاسبه می شود:
1.0 / (1.0 + e^-x)
جایی که e یک ثابت ریاضی است که پایه لگاریتم طبیعی است. با مثال زیر میتوانیم شهودی برای شکل این تابع بدست آوریم.

اجرای مثال، خروجی ها را برای محدوده ای از مقادیر محاسبه می کند و نموداری از ورودی ها در مقابل خروجی ها ایجاد می کند. میتوانیم شکل S آشنا تابع فعالسازی سیگموئید را ببینیم.
تابع فعال سازی خطی اصلاح شده در لایه پنهان
تابع فعالسازی خطی اصلاحشده یا تابع فعالسازی ReLU، شاید رایجترین تابعی باشد که برای لایههای پنهان استفاده میشود. رایج است زیرا هم پیاده سازی آن ساده است و هم در غلبه بر محدودیت های دیگر توابع فعال سازی محبوب قبلی مانند Sigmoid و Tanh موثر است. به طور خاص، نسبت به شیب های ناپدید شدنی که از آموزش مدل های عمیق جلوگیری می کند، کمتر حساس است، اگرچه ممکن است از مشکلات دیگری مانند واحدهای اشباع یا “مرده” رنج ببرد.
تابع ReLU به صورت زیر محاسبه می شود:
حداکثر (0.0، x)
به این معنی که اگر مقدار ورودی (x) منفی باشد، مقدار 0.0 برگردانده می شود، در غیر این صورت، مقدار برگردانده می شود.
با مثال زیر می توانیم شهودی برای شکل این تابع بدست آوریم.

اجرای مثال، خروجیها را برای محدودهای از مقادیر محاسبه میکند و نموداری از ورودیها در مقابل خروجیها ایجاد میکند. میتوانیم شکل پیچ خوردگی آشنا تابع فعالسازی ReLU را ببینیم
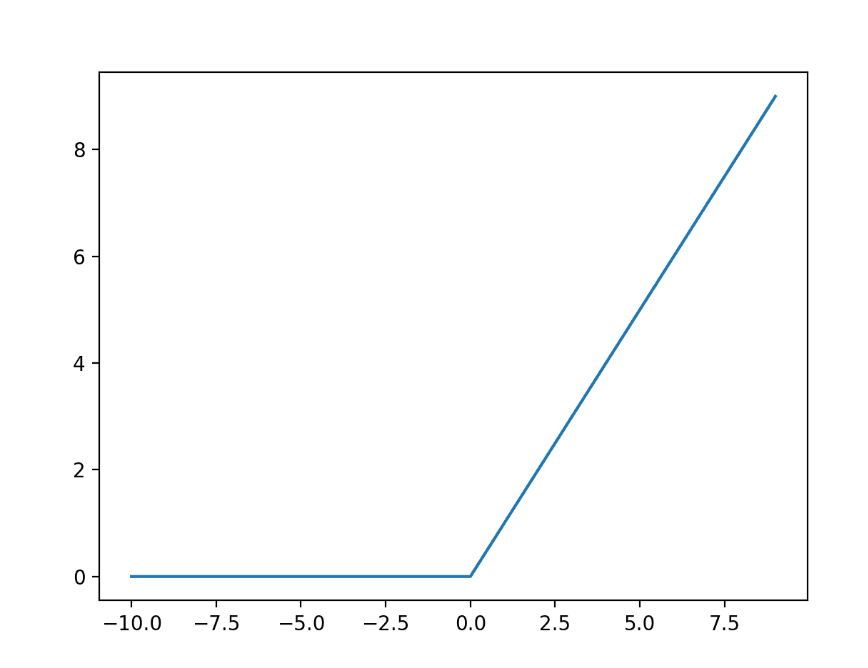
تابع فعال سازیTanh لایه پنهان
تابع فعال سازی مماس هذلولی به سادگی به عنوان تابع Tanh (همچنین “tanh” و “TanH”) نامیده می شود. شباهت زیادی به تابع فعال سازی سیگموئید دارد و حتی همان S شکل را دارد. تابع هر مقدار واقعی را به عنوان ورودی می گیرد و مقادیر را در بازه 1- تا 1 خروجی می دهد. هرچه ورودی بزرگتر باشد (مثبت تر)، مقدار خروجی به 1.0 نزدیکتر خواهد بود، در حالی که هرچه ورودی کوچکتر (منفی تر) باشد، نزدیکتر است. خروجی به -1.0 خواهد بود. تابع فعال سازی Tanh به صورت زیر محاسبه می شود:
(e^x – e^-x) / (e^x + e^-x)
جایی که e یک ثابت ریاضی است که پایه لگاریتم طبیعی است. با مثال زیر می توانیم شهودی برای شکل این تابع بدست آوریم
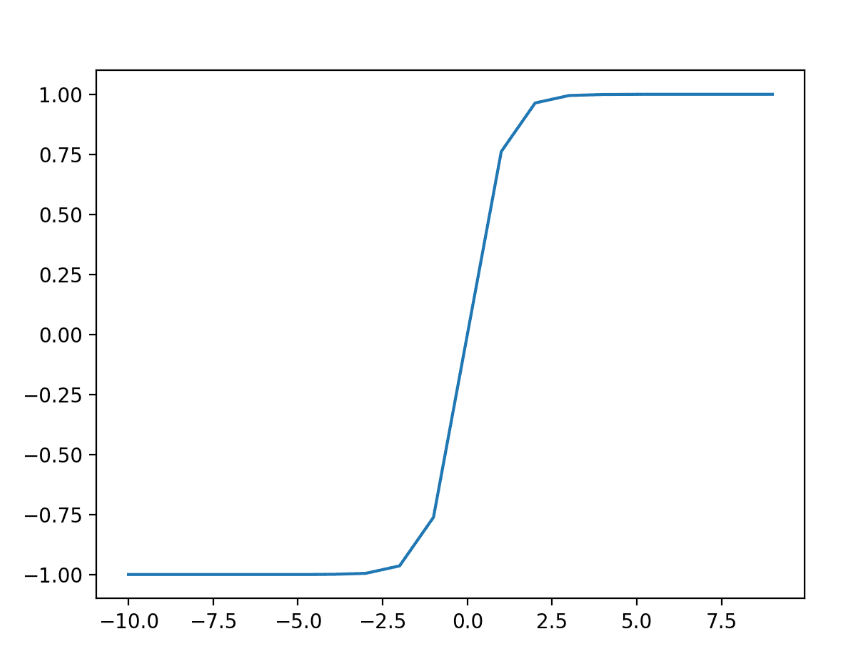
نحوهی انتخاب تابع فعالسازی مناسب برای لایهی پنهان
یک شبکه عصبی معمولاً از سه نوع لایه تشکیل شده است: لایه ورودی، لایه(های) پنهان و لایه خروجی. لایه ورودی فقط داده های ورودی را نگه می دارد و هیچ محاسبه ای انجام نمی شود. بنابراین، هیچ تابع فعال سازی در آنجا استفاده نمی شود. ما باید از یک تابع فعال سازی غیر خطی در داخل لایه های پنهان در یک شبکه عصبی استفاده کنیم. این به این دلیل است که برای یادگیری الگوهای پیچیده باید غیرخطی بودن را به شبکه معرفی کنیم. بدون توابع فعالسازی غیرخطی، یک شبکه عصبی با لایههای پنهان بسیاری به یک مدل رگرسیون خطی غولپیکر تبدیل میشود که برای یادگیری الگوهای پیچیده از دادههای دنیای واقعی بیفایده است. عملکرد یک مدل شبکه عصبی بسته به نوع تابع فعال سازی که در داخل لایه های پنهان استفاده می کنیم، به طور قابل توجهی متفاوت خواهد بود. همچنین باید از یک تابع فعال سازی در داخل لایه خروجی در شبکه عصبی استفاده کنیم. انتخاب تابع فعال سازی به نوع مشکلی که می خواهیم حل کنیم بستگی دارد.
به طور سنتی، تابع فعال سازی سیگموئید تابع فعال سازی پیش فرض در دهه 1990 بود. شاید از اواسط تا اواخر دهه 1990 تا 2010، تابع Tanh تابع فعال سازی پیش فرض برای لایه های پنهان بود. تابع فعال سازی مورد استفاده در لایه های پنهان معمولاً بر اساس نوع معماری شبکه عصبی انتخاب می شود. مدلهای شبکه عصبی مدرن با معماریهای رایج، مانند MLP و CNN، از تابع فعالسازی ReLU یا برنامههای افزودنی استفاده میکنند. در شبکه های عصبی مدرن، توصیه پیش فرض استفاده از واحد خطی اصلاح شده یا ReLU است.
شبکههای RNN هنوز معمولاً از توابع فعالسازی Tanh یا sigmoid یا حتی از هر دو استفاده میکنند. به عنوان مثال، LSTM معمولاً از فعال سازی Sigmoid برای اتصالات مکرر و از فعال سازی Tanh برای خروجی استفاده می کند.
پرسپترون چند لایه (MLP): تابع فعال سازی ReLU.
شبکه عصبی کانولوشنال (CNN): تابع فعال سازی ReLU.
شبکه عصبی مکرر: تابع فعال سازی Tanh و/یا Sigmoid.
اگر مطمئن نیستید که از کدام عملکرد فعال سازی برای شبکه خود استفاده کنید، چند مورد را امتحان کنید و نتایج را با هم مقایسه کنید.
تابع فعالسازی برای لایههای خروجی
فعال سازی برای لایه های خروجی لایه خروجی لایه ای در مدل شبکه عصبی است که مستقیماً یک پیش بینی را خروجی می دهد. همه مدلهای شبکه عصبی پیشخور دارای یک لایه خروجی هستند. شاید بخواهید سه تابع فعال سازی را برای استفاده در لایه خروجی در نظر بگیرید. آن ها هستند:
خطی لجستیک (سیگموئید) سافت مکس این لیست کاملی از توابع فعال سازی مورد استفاده برای لایه های خروجی نیست، اما آنها بیشترین استفاده را دارند.
تابع فعالسازی خروجی خطی
تابع فعالسازی خطی «هویت» (ضرب در 1.0) یا «بدون فعالسازی» نیز نامیده میشود. زیرا تابع فعال سازی خطی به هیچ وجه مجموع وزنی ورودی را تغییر نمی دهد و در عوض مقدار را مستقیما برمی گرداند. با مثال زیر می توانیم درک بهتری با توجه به شکل این تابع بدست آوریم.
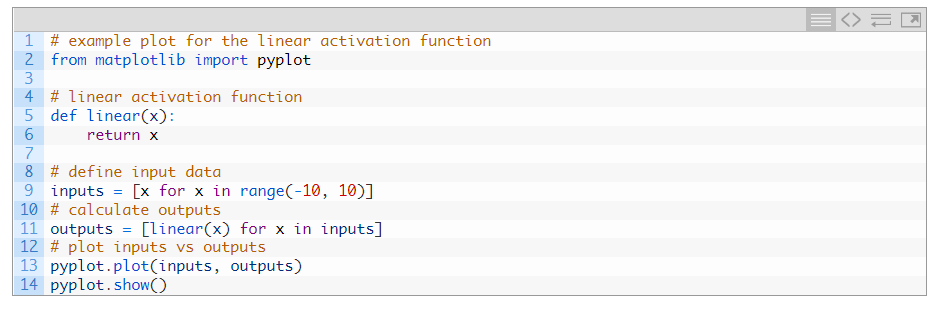
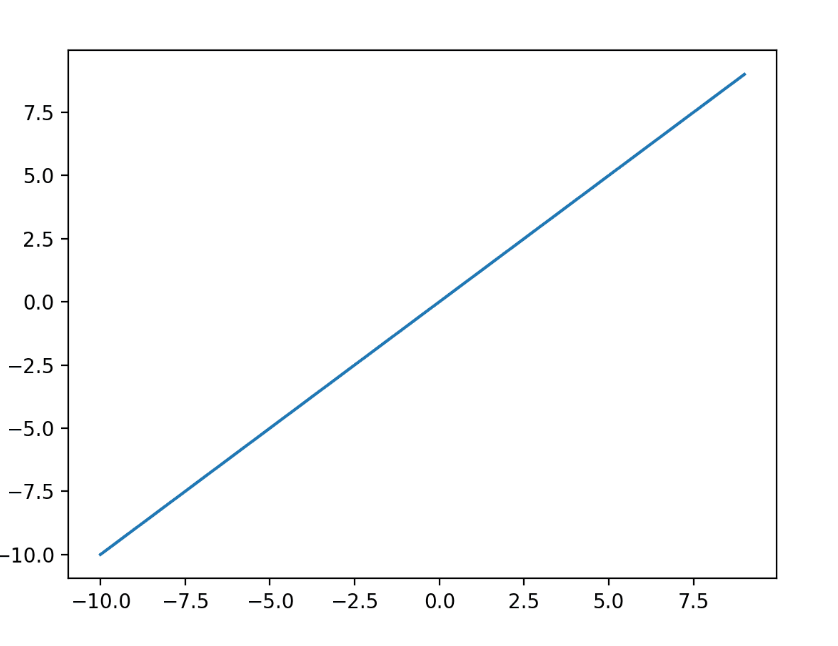
مقادیر هدف مورد استفاده برای آموزش یک مدل با تابع فعال سازی خطی در لایه خروجی معمولاً قبل از مدلسازی با استفاده از تبدیلهای عادی یا استانداردسازی مقیاسبندی میشوند.
تابع فعالسازی خروجی سیگموئید
سیگموئید تابع فعال سازی لجستیک در بخش قبل توضیح داده شد. با این وجود، برای افزودن مقداری تقارن، میتوانیم شکل این تابع را با مثال زیر بررسی کنیم.
برچسبهای هدف مورد استفاده برای آموزش یک مدل با تابع فعالسازی سیگموئید در لایه خروجی دارای مقادیر 0 یا 1 خواهند بود.
تابع فعالسازی خروجی سافتمکس
تابع softmax بردار مقادیری را به دست میدهد که مجموع آنها 1.0 است که میتواند به عنوان احتمالات عضویت در کلاس تفسیر شود. مربوط به تابع argmax است که برای همه گزینه ها 0 و برای گزینه انتخابی 1 خروجی می دهد. Softmax یک نسخه «نرمتر» از argmax است که امکان خروجی شبیه به احتمال را از تابع برنده همه چیز فراهم میکند.
به این ترتیب، ورودی تابع بردار مقادیر واقعی و خروجی بردار با همان طول با مقادیری است که مجموع آنها برابر با 1.0 است.
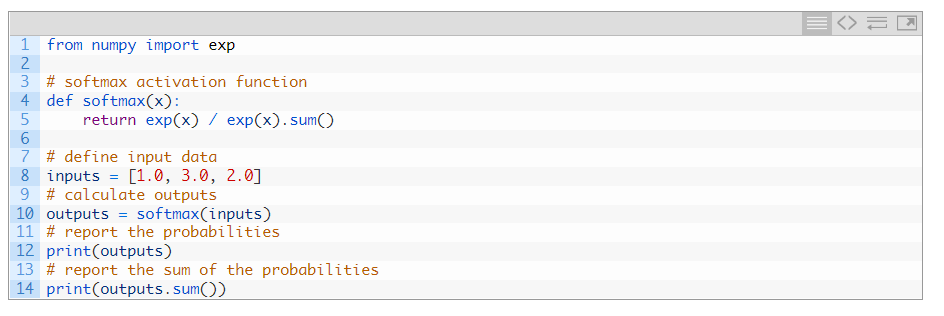
تابع softmax به صورت زیر محاسبه می شود:
e^x / sum(e^x)
که در آن x بردار خروجی ها و e یک ثابت ریاضی است که پایه لگاریتم طبیعی است.
ما نمی توانیم تابع softmax را رسم کنیم، اما می توانیم مثالی از محاسبه آن در پایتون ارائه دهیم.

نحوهی انتخاب تابع فعال سازی خروجی برای شبکهی عصبی
شما باید تابع فعال سازی را برای لایه خروجی خود بر اساس نوع مشکل پیش بینی که در حال حل آن هستید انتخاب کنید. به طور خاص، نوع متغیری که پیش بینی می شود. به عنوان مثال، ممکن است مسائل پیش بینی را به دو گروه اصلی، پیش بینی یک متغیر طبقه بندی (طبقه بندی) و پیش بینی یک متغیر عددی (رگرسیون) تقسیم کنید. اگر مشکل شما مشکل رگرسیون است، باید از تابع فعال سازی خطی استفاده کنید. رگرسیون: یک گره، فعال سازی خطی. اگر مشکل شما یک مشکل طبقه بندی است، سه نوع اصلی از مشکلات طبقه بندی وجود دارد و هر کدام ممکن است از یک تابع فعال سازی متفاوت استفاده کنند. پیش بینی یک احتمال یک مشکل رگرسیونی نیست. طبقه بندی است. در تمام موارد طبقهبندی، مدل شما احتمال عضویت در کلاس را پیشبینی میکند (مثلاً احتمال اینکه یک مثال به هر کلاس تعلق دارد) که میتوانید با گرد کردن (برای sigmoid) یا argmax (برای softmax) به یک برچسب کلاس واضح تبدیل کنید. اگر دو کلاس انحصاری متقابل وجود داشته باشد (طبقه بندی باینری)، لایه خروجی شما یک گره خواهد داشت و باید از تابع فعال سازی سیگموئید استفاده شود. اگر بیش از دو کلاس انحصاری متقابل وجود داشته باشد (طبقه بندی چند کلاسه)، لایه خروجی شما یک گره در هر کلاس خواهد داشت و باید از یک فعال سازی softmax استفاده شود. اگر دو یا چند کلاس متقابلا شامل (طبقه بندی چند برچسبی) وجود داشته باشد، لایه خروجی شما یک گره برای هر کلاس خواهد داشت و از تابع فعال سازی سیگموئید استفاده می شود.
طبقه بندی باینری: یک گره، فعال سازی سیگموئید.
طبقه بندی چند کلاسه: یک گره در هر کلاس، فعال سازی softmax.
طبقه بندی چند برچسبی: یک گره در هر کلاس، فعال سازی سیگموئید
سخن آخر
در این مطلب یک بررسی عمیق در ساختار و جایگاه تابع فعالسازی در شبکهی عصبی، عملکرد هر یک از انواع تابع فعالسازی، تفاوت لایهی پنهان و خروجی و نحوهی انتخاب تابع فعالسازی داشتهایم. اگر به توابع فعالساری علاقه دارید حتماً به سری آموزشهای تابع فعالسازی در پرتال هوش مصنوعی سر بزنید. امیدوارم این مطلب برای شما مفید بوده باشد.