در مسیر یادگیری و کسب مهارت در زمینهی یادگیری ماشین (Machine learning)، یادگیری عمیق (Deep learning) و هوش مصنوعی (AI) و همچنین بدست آوردن تخصص در حوزههای مختلف هوش مصنوعی درک و دانستن مفاهیم اصلی و بنیادی نقش مهمی در مسیر حرفهای هر فرد دارند. هوش مصنوعی، یادگیری ماشینی و یادگیری عمیق (دیپ لرنینگ) به فناوریهای مورد بحث در دنیای تجاری امروز تبدیل شدهاند که احتمالاً حداقل یک بار به اسمشان در اخبار بر خوردهاید. شرکتها و به مرور زمان دولتها از این فناوریها در گسترهی وسیعی از صنایع و حتی در سادهترین کارهای روزمرهی انسانها به عنوان جایگزین و تسهیل کننده استفاده میکنند. اگرچه این اصطلاحات دائماً در گفتگوهای تجاری، گروهها و شرکتهای فناوری و… در سراسر جهان به کار میروند، اما بسیاری از مردم در تمایز بین آنها مشکل دارند. این در این مطلب به بررسی مفاهیم و کاربرد آنها و تفاوتشان با یکدیگر میپردازیم تا درک روشنی از هوش مصنوعی، یادگیری ماشینی، و یادگیری عمیق و تفاوت آنها با یکدیگر به دست آورید.
“هوش مصنوعی برای از بین بردن بشریت لازم نیست شر باشد، اگر هوش مصنوعی هدفی داشته باشد و انسانیت را در مسیر خود مبنا قرار دهد، بشریت را به طور طبیعی بدون حتی فکر کردن به آن، بدون هیچ احساساتی، نابود خواهد کرد.”
ایلان ماسک، کارآفرین فناوری و سرمایهگذار
در حوزهی یادگیری عمیق(deep learning)، الگوریتمهایی که اکنون استفاده میکنیم، نسخههایی از الگوریتمهایی هستند که در دهههای 1980 و 1990 توسعه میدادیم. در آن زمان مردم نسبت به آنها بسیار خوشبین بودند، اما امروزه مشخص شده که آنها آنگونه مه انتظار داشتیهایم بازدهای نداشتهاند.”
جفری هینتون
لیست مطالب
انواع هوش مصنوعی بر اساس نوع و پیچیدگی وظایفی که بر عهده دارد.
نگاهی گذرا به تاریخچه و روند دست آوردهای هوش مصنوعی
شرح تفاوت هوش مصنوعی و ماشین لرنینگ و دیپ لرنینگ
تفاوت هوش مصنوعی و یادگیری ماشین چیست؟
یادگیری عمیق و یا شبکههای عصبی چیست؟
اهمیت دیتا در هوش مصنوعی، یادگیری ماشین و دیپ لرنینگ.
بهترین پلتفرم های موتور جستجو مجموعه داده برای چالش یادگیری ماشین
هوش مصنوعی (Artificial intelligence) چیست؟
امروزه استفاده از فناوری هوش مصنوعی تبدیل به یکی از تبلیغات کلیدی اکثر شرکتها و مؤسسات شده است، در حالی که عموم مردم و حتی خود شرکتها دقیقاً مفهوم، ماهیت و کاربردهای هوش مصنوعی را نمیدانند. تعریف رسمی هوش مصنوعی (Artificial intelligence) به شرح زیر است:
تلاش برای خودکارسازی و هوشمندسازی عملکردهای فکری که معمولاً به طریقی توسط انسان انجام میشود.
تعریف بالا یک توصیف بسیار کلی از هوش مصنوعی است، در حالی که با توجه به اینکه هر یک از ما ممکن است از عملکردهای فکری توصیف متفاوتی داشته باشیم، هوش مصنوعی هم در همان سو برای ما کاربردها و جلوههای متفاوتی خواهد داشت. برای درک بهتر از ماهیت هوش مصنوعی نگاهی کوتاه و خلاصه به تاریخچهی آن میاندازیم که چگونه هوش مصنوعی شکل گرفت و هوش مصنوعی در طول زمان چگونه تکامل یافته است.
داستان کوتاهی از اولین و سادهترین عملکردهای هوش مصنوعی
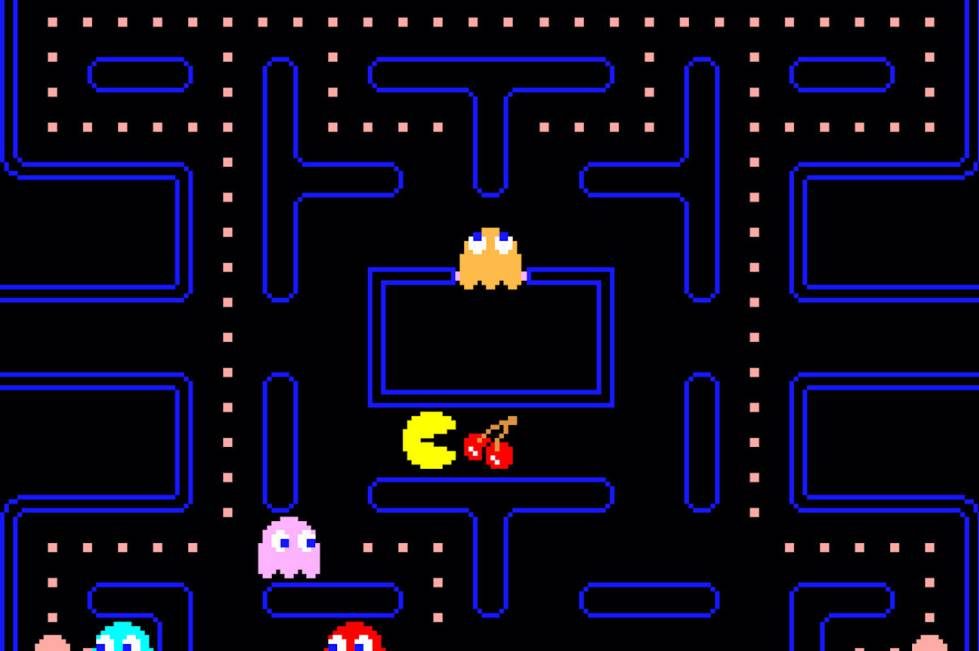
در سال ۱۹۵۰ یکی از انواع سؤالات که جزء دغدغههای محققین و دانشمندان بود، این بود که: آیا کامپیوترها میتوانند فکر کنند؟ آیا میتوانیم کامپیوترها را وادار به فکر کردن کنیم؟ در آن زمان تغییر روش کار کامپیوترها از عمل کردن بر اساس کدهای برنامه نویسی شده به فکر کردن به صورت خودکار و قادر به تصمیم گیری بودن همانند انسانها از اهداف متخصصین بود. در این حال اصطلاح هوش مصنوعی به نوعی ابداع و خلق شد. در نگاه مردم در روزهای اولیهی ظهور هوش مصنوعی، هوش مصنوعی(Artificial intelligence) صرفاً برنامهای بر اساس مجموعهای از قوانین از پیش تعریف شده بود. بنابراین در دهههای ۵۰ و ۶۰، هوش مصنوعی شطرنج و یا X و O بازی میکرد که صرفاً مجموعهای از کدهایی بود که توسط انسانها نوشته شده بود و خبری از الگوریتمهای حجیم یادگیری عمیق و یادگیری ماشین نبود. در دههی ۵۰ ـ ۶۰ اگر از هوش مصنوعی خواستهای داشتید به سادگی در قالب کدنویسی به آن فرمان میدادید که این خواسته را دارید و در ادامهی آن چه اتفاقاتی خواهد افتاد و چه فاکتورهایی تأثیر گذار هستند، هوش مصنوعی هم بر طبق تعاریف شما عمل میکرد. در آن زمان هوش مصنوعی خوب معادل مهارت در نوشتن مجموعهی قوانین به صورت ساده و روان و قابل اجرا بود. در واقع دقت کنید هوش مصنوعی لزوماً حجم زیادی از کدها نیست که ساده یا پیچیده باشند بلکه اساساً شبیهسازی یک فعالیت فکری مانند یک بازی که انسان با کامپیوتر انجام میدهد، که در قالب کدهای برنامهنویسی میباشد. برای مثال در بازی Pacman , هوش مصنوعی در این بازی همان Ghost یا روح میباشد که با پیروی از الگوریتم مسیریابی ساده کامپیوتر تلاش میکند راهی را کشف کند تا بتواند خود را به Pacman برساند، در حالی که در این بازی از تکنولوژی یادگیری ماشین و یا دیپ لرنینگ استفادهای نشده است اما بر خلاف تصور عموم به عنوان هوش مصنوعیای در این سطح در نظر گرفته میشود.

پس به طور خلاصه برای ساختن یک هوش مصنوعی الزاماً به داشتن مجموعهای حجیم و دیوانه وار از الگوریتمهای یادگیری عمیق و یادگیری ماشین نیازی نداریم بلکه لزوماً هر الگوریتم و مجموعهای از کدها که رفتار عقلانی یا احساسی انسان را شبیه سازی کند، هوش مصنوعی محسوب میشود. بدیهی است که امروزه هوش مصنوعی به حوزهی بسیار پیچیده و گستردهای تکامل یافته است که شامل یادگیری ماشین، یادگیری عمیق و تکنیکهای بسیار دیگری میباشد، که در ادامه هر یک را بررسی خواهیم کرد.
محدودیت اصلی در تعریف هوش مصنوعی بهعنوان «ساخت ماشینهایی که هوشمند هستند» این است که این تعریف در واقع توضیح نمیدهد که هوش مصنوعی چیست و چه چیزی یک ماشین را هوشمند میکند. هوش مصنوعی یک علم بین رشتهای با رویکردهای متعدد است، اما پیشرفتها در یادگیری ماشینی و یادگیری عمیق تقریباً در هر بخش از صنعت فناوری یک تغییر پارادایم را ایجاد میکند.
استوارت راسل و پیتر نورویگ نویسندگان در حوزهی فناوری و تکنولوژی در کتاب خود هوش مصنوعی را به این گونه تعریف میکنند: هوش مصنوعی رویکردی مدرن است که با متحد کردن کار خود پیرامون موضوع عوامل هوشمند در ماشینها، خود را به مفهوم هوش مصنوعی نزدیک میکند. با در نظر گرفتن این موضوع، هوش مصنوعی «مطالعه عواملی است که ادراکاتی را از محیط دریافت میکنند و اعمالی را با توجه به دیتای ورودی خود و قوانین از پیش تعریف شده انجام میدهد».
انواع هوش مصنوعی بر اساس نوع و پیچیدگی وظایفی که بر عهده دارد:
بر اساس نوع و پیچیدگی وظایفی که یک سیستم قادر به انجام آن است، هوش مصنوعی را می توان به چهار دسته تقسیم کرد.
ماشینهای واکنشگرا (Reactive Machines):
قادر به درک و واکنش به دنیای مقابل در هنگام انجام مجموعهای از وظایف محدود هستند.این مدل هوش مصنوعی قدیمیترین شکل از سیستمهای هوش مصنوعی است که توانایی بسیار محدودی دارد. ماشینهای واکنشگرا از توانایی ذهن انسان برای پاسخگویی به انواع مختلف محرکها تقلید میکنند. این ماشینها عملکرد مبتنی بر حافظه ندارند. این بدان معنا است که چنین ماشینهایی نمی توانند از تجربیات به دست آمده قبلی در اقدامات فعلی خود استفاده کنند، یعنی این ماشین ها توانایی “یادگیری” را ندارند. این ماشینها فقط میتوانند برای پاسخدهی خودکار به مجموعه یا ترکیبی از ورودیها استفاده شوند. یک نمونه محبوب از یک ماشین هوش مصنوعی واکنشگرا، Deep Blue IBM است، ماشینی که در سال 1997 استاد بزرگ شطرنج گری کاسپاروف را شکست داد.
تئوری ذهن (Theory of Mind):
این نوع از هوش مصنوعی قادر به تصمیم گیری بر اساس درک خود از احساس دیگران است. در حال حاضر به عنوان یک مفهوم یا یک پروژهی در حال پیشرفت وجود دارند. تئوری ذهن هوش مصنوعی سطح بعدی سیستمهای هوش مصنوعی است که محققان در حال حاضر مشغول تحقیقات و ارتقای این نوع از هوش مصنوعی هستند. هوش مصنوعی سطح تئوری ذهن قادر خواهد بود با تشخیص نیازها، عواطف، باورها و فرآیندهای فکری، نهادهایی را که با آنها در تعامل است، درک کند. در حالی که هوش هیجانی مصنوعی در حال حاضر یک صنعت نوپا و موضوع مورد علاقه محققان برجسته هوش مصنوعی است، دستیابی به سطح تئوری ذهن هوش مصنوعی نیازمند توسعه در سایر شاخههای هوش مصنوعی نیز خواهد بود. این به دلیل این است که برای درک واقعی نیازهای انسان، ماشینهای هوش مصنوعی باید انسانها را بهعنوان افرادی درک کنند که ذهنشان میتواند توسط عوامل متعددی شکل بگیرد.
خودآگاهی (Self-Awareness):
می تواند با آگاهی در سطح انسان عمل کند و وجود خود را درک کند.این مرحله نهایی توسعه هوش مصنوعی است که در حال حاضر فقط به سطح خوبی از پیشرفت رسیده است. هوش مصنوعی خودآگاه، که به طور توضیحی، هوش مصنوعی است که چنان به مغز انسان شبیه است که خودآگاهی را توسعه داده است. ایجاد این نوع هوش مصنوعی، هدف نهایی تمام تحقیقات هوش مصنوعی بوده و خواهد بود. این نوع هوش مصنوعی نه تنها قادر به درک و برانگیختن احساسات در افرادی است که با آنها در تعامل است، بلکه دارای احساسات، نیازها، باورها و تمایلات بالقوه خود است. و این همان نوع هوش مصنوعی است که افراد برجسته این فناوری دربارهی آن هشدار دادهاند. اگرچه توسعه خودآگاهی به طور بالقوه میتواند پیشرفت ما را به عنوان یک تمدن با جهشی قابل توجه افزایش دهد، اما می تواند به طور بالقوه منجر به فاجعه شود. این به این دلیل است که هوش مصنوعی زمانی که خودآگاه شود، میتواند ایدههایی مانند حفظ و ارتقای خود داشته باشد که ممکن است به طور مستقیم یا غیرمستقیم پایانی برای بشریت باشد، زیرا چنین موجودی به راحتی میتواند بر عقل هر انسانی غلبه کند و طرحهای پیچیدهای را بر علیه انسانیت طراحی کند.
حافظه محدود(Limited Memory):
میتواند دادهها و پیشبینیهای گذشته را ذخیره کند تا پیشبینیهای را از آنچه ممکن است در آینده رخ دهد انجام دهد. ماشین حافظه محدود ماشینهایی هستند که علاوه بر داشتن قابلیتهای ماشینهای صرفا واکنشپذیر، توانایی یادگیری از دادههای گذشته برای تصمیمگیری را نیز دارند. تقریباً تمام برنامه های کاربردی موجود که می شناسیم در این دسته از هوش مصنوعی قرار می گیرند. تمام سیستمهای هوش مصنوعی امروزی، مانند سیستمهایی که از یادگیری عمیق استفاده میکنند، با حجم زیادی از دادههای آموزشی که در حافظه خود ذخیره میکنند، آموزش میبینند تا یک مدل مرجع برای حل مشکلات آینده تشکیل دهند. به عنوان مثال، یک هوش مصنوعی تشخیص تصویر با استفاده از هزاران تصویر و برچسبهای آنها آموزش داده میشود تا نام اشیایی را که اسکن میکند به آن آموزش دهد. هنگامی که یک تصویر توسط چنین هوش مصنوعی اسکن میشود، از تصاویر آموزشی به عنوان مرجع برای درک محتوای تصویر ارائه شده به آن استفاده می کند و بر اساس “تجربه یادگیری” خود، تصاویر جدید را با دقت فزاینده برچسب گذاری می کند. تقریباً تمام برنامههای کاربردی هوش مصنوعی امروزی، از چتباتها و دستیاران مجازی گرفته تا وسایل نقلیه خودران، همگی توسط هوش مصنوعی با حافظه محدود هدایت میشوند.
نگاهی گذرا به تاریخچه و روند دست آوردهای هوش مصنوعی
رباتهای هوشمند و موجودات مصنوعی اولین بار در اسطورههای یونان باستان در دوران باستان ظاهر شدند. توسعهی قیاس ارسطو و استفادهاش از استدلال قیاسی یک لحظه کلیدی در جستجوی بشر برای درک هوش و خودآگاهی خود بود. در حالی که ریشههای این مفهوم به گذشته برمیگردد. بذر هوش مصنوعی مدرن توسط فیلسوفانی کاشته شد که تلاش کردند فرآیند تفکر انسان را به عنوان ابزاری مکانیکی از نمادها توصیف کنند. این کار با اختراع کامپیوتر دیجیتال قابل برنامهریزی در دهه 1940 به اوج خود رسید، ماشینی که بر اساس استدلال ریاضی عمل میکرد. این دستگاه و ایدههای پشت آن الهام بخش تعداد انگشت شماری از دانشمندان شد تا به طور جدی درباره امکان ساخت مغز الکترونیکی بحث کنند. تاریخچهی هوش مصنوعی همانطور که امروز به آن فکر میکنیم کمتر از یک قرن است. در ادامه نگاهی گذرا به برخی از مهمترین رویدادها در تکامل هوش مصنوعی میاندازیم.
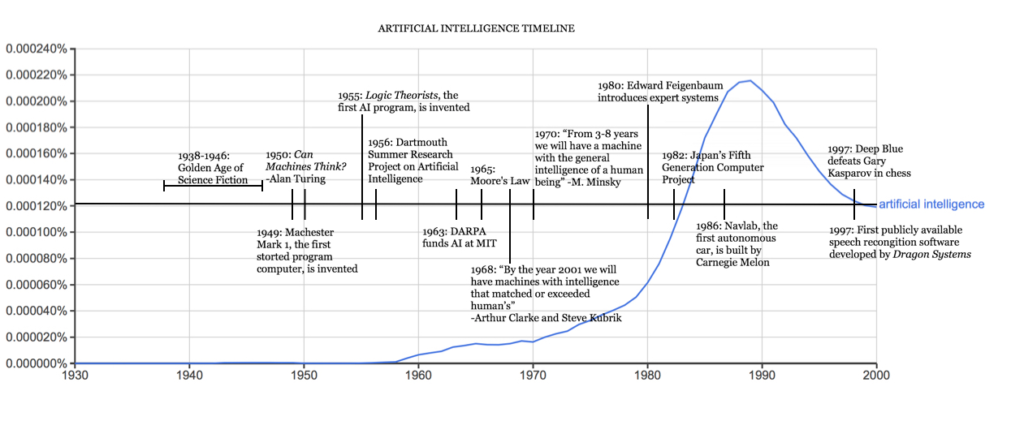
دهه 1940
سال(1943) وارن مک کالو و والتر پیتس مقاله “حساب منطقی ایده های ماندگار در فعالیت عصبی” را منتشر کردند که اولین مدل ریاضی را برای ساخت شبکه عصبی پیشنهاد می کند.
سال(1949) دونالد هب در کتاب خود با نام سازمان رفتار: یک نظریه عصب روانشناختی، این نظریه را پیشنهاد میکند که مسیرهای عصبی از تجربیات ایجاد میشوند و ارتباط بین نورونها هر چه بیشتر مورد استفاده قرار گیرد قویتر میشود. یادگیری Hebbian همچنان یک مدل مهم در هوش مصنوعی است.
(1942) آیزاک آسیموف سه قانون رباتیک را منتشر کرد، ایدهای که معمولاً در رسانه های علمی تخیلی در مورد اینکه چگونه هوش مصنوعی نباید به انسان آسیب برساند یافت میشود.
دههی 1950
(1950) آلن تورینگ مقاله «ماشینهای محاسباتی و هوش» را منتشر کرد و ایدهای را پیشنهاد کرد که اکنون به عنوان آزمون تورینگ شناخته میشود، روشی برای تعیین هوشمند بودن یک ماشین.
(1950) ماروین مینسکی و دین ادموندز، دانشجویان کارشناسی هاروارد، SNARC، اولین کامپیوتر شبکه عصبی را ساختند.
(1950) کلود شانون مقاله “برنامه ریزی یک کامپیوتر برای بازی شطرنج” را منتشر کرد.
(1952) آرتور ساموئل یک برنامه خودآموز برای بازی چکرز ساخت.
(1954) آزمایش ترجمه ماشینی جورج تاون-IBM به طور خودکار 60 جمله روسی را که با دقت انتخاب شده بودند به انگلیسی ترجمه کرد.
(1956) عبارت “هوش مصنوعی” در پروژه تحقیقاتی تابستانی دارتموث در مورد هوش مصنوعی ابداع شد. این کنفرانس به رهبری جان مک کارتی به عنوان زادگاه هوش مصنوعی در نظر گرفته میشود.
(1956) آلن نیول و هربرت سایمون نظریه پرداز منطق (LT) را نشان دادند. ( اولین برنامه استدلال).
(1958) جان مک کارتی زبان برنامه نویسی هوش مصنوعی Lisp را توسعه داد و “برنامه هایی با عقل سلیم” را منتشر کرد، مقالهای که ایدهی فرضی را پیشنهاد میداد، یک سیستم هوش مصنوعی کامل با توانایی یادگیری از تجربه به اندازه انسانها.
(1959) آلن نیوول، هربرت سایمون و جی سی شاو برنامه حل مشکل عمومی (GPS) را توسعه دادند، برنامهای که برای تقلید از حل مسئله انسان طراحی شده است.
(1959) هربرت گلرنتر برنامهی اثبات قضیه هندسه را توسعه داد.
(1959) آرتور ساموئل اصطلاح “یادگیری ماشینی” را در زمانی که در IBM کار میکرد ابداع کرد.
(1959) جان مک کارتی و ماروین مینسکی پروژه هوش مصنوعی MIT را پیدا کردند.
دهه 1960
(1963) جان مک کارتی آزمایشگاه هوش مصنوعی را در استنفورد راه اندازی کرد.
(1966) گزارش کمیته مشورتی پردازش خودکار زبان (ALPAC) توسط دولت ایالات متحده، عدم پیشرفت در تحقیقات ترجمه ماشینی را شرح داد، یک ابتکار بزرگ جنگ سرد با وعده ترجمه خودکار و فوری زبان روسی. گزارش ALPAC منجر به لغو تمام پروژههای MT با بودجه دولت شد.
(1969) اولین سیستمهای خبرهی موفق در DENDRAL، یک برنامه XX، و MYCIN، طراحی شده برای تشخیص عفونت های خون، در استنفورد ایجاد شدند.
دهه 1970
(1972) زبان برنامه نویسی منطقی PROLOG ایجاد شد.
(1973) گزارش لایتهیل، که ناامیدیها در تحقیقات هوش مصنوعی را شرح میداد، توسط دولت بریتانیا منتشر شد و منجر به کاهش شدید بودجه برای پروژههای هوش مصنوعی شد.
(1974-1980) ناامیدی از پیشرفت توسعه هوش مصنوعی منجر به کاهش عمده DARPA در کمک هزینه تحصیلی شد. همراه با گزارش قبلی ALPAC و گزارش Lighthill سال قبل، بودجه هوش مصنوعی تقریباً به کمترین میزان رسید و تحقیقات متوقف شدند. این دوره به “اولین زمستان هوش مصنوعی” معروف است.
دهه 1980
(1980) Digital Equipment Corporations R1 (همچنین به عنوان XCON شناخته می شود)، اولین سیستم متخصص تجاری توسعه داده شد. R1 که برای پیکربندی سفارشات برای سیستمهای رایانهای جدید طراحی شده است، رونق سرمایهگذاری در سیستمهای خبره را آغاز میکند که تا بیشتر دهه دوام خواهد داشت و عملاً به اولین زمستان هوش مصنوعی پایان میدهد.
(1982) وزارت تجارت و صنعت بین المللی ژاپن پروژهی جاه طلبانه سیستمهای کامپیوتری نسل پنجم را راه اندازی کرد. هدف FGCS توسعهی عملکرد ابررایانهای مانند و پلتفرمی برای توسعه هوش مصنوعی بود.
(1983) در پاسخ به FGCS ژاپن، دولت ایالات متحده ابتکار محاسبات استراتژیک را برای ارائه تحقیقات با بودجه دارپا در محاسبات پیشرفته و هوش مصنوعی راه اندازی کرد.
(1985) شرکتها سالانه بیش از یک میلیارد دلار برای سیستمهای خبره هزینه میکردند و یک صنعت کامل به نام بازار ماشینهای لیسپ برای حمایت از آنها به وجود میآید. شرکت هایی مانند Symbolics و Lisp Machines Inc. کامپیوترهای تخصصی را برای اجرا بر روی زبان برنامه نویسی هوش مصنوعی Lisp ساختند.
(1987-1993) با بهبود فناوری محاسبات، جایگزینهای ارزانتری پدیدار شد و بازار ماشینهای Lisp در سال 1987 سقوط کرد و “زمستان دوم هوش مصنوعی” را آغاز کرد. در این دوره، سیستم های پیشرفته برای نگهداری و به روزرسانی بسیار گران بودند و در نهایت از بین رفتند.
دهه 1990
(1991) نیروهای ایالات متحده، DART، یک ابزار برنامهریزی لجستیک خودکار را در طول جنگ خلیج فارس مستقر کردند.
(1992) ژاپن پروژه FGCS را در سال 1992 خاتمه داد و دلیل آن شکست در دستیابی به اهداف بلندپروازانه ای است که یک دهه پیش از آن مشخص شده بود.
(1993) دارپا به ابتکار محاسبات استراتژیک در سال 1993 پس از صرف نزدیک به 1 میلیارد دلار و بسیار کمتر از انتظارات، پایان داد.
(1997) دیپ بلو IBM، قهرمان شطرنج جهان، گری کاسپاروف را شکست داد.
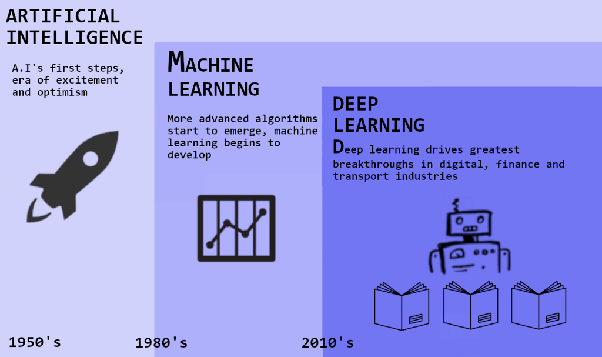
دهه 2010
(2005) ارتش ایالات متحده سرمایه گذاری در ربات های خودمختار مانند “Big Dog” از Boston Dynamics و “PackBot” iRobot را آغاز کرد.
(2008) گوگل پیشرفت هایی در تشخیص گفتار ایجاد کرد و این ویژگی را در برنامه آیفون خود معرفی کرد.
(2011) اپل سیری، یک دستیار مجازی مجهز به هوش مصنوعی را از طریق سیستم عامل iOS خود منتشر شد.
(2012) Andrew Ng، بنیانگذار پروژه Google Brain Deep Learning، با استفاده از الگوریتمهای یادگیری عمیق 10 میلیون ویدیوی یوتیوب را به عنوان یک مجموعه آموزشی به شبکه عصبی تغذیه میکند دریافت کرد. شبکه عصبی یاد گرفت که گربه را بدون اینکه به او گفته شود گربه چیست، بشناسد، این امر آغازگر دوران پیشرفت شبکههای عصبی و بودجه یادگیری عمیق است.
(2014) گوگل اولین خودروی خودران را ساخت که در آزمون رانندگی دولتی موفق شد.
(2014) الکسای آمازون، یک دستگاه هوشمند خانه مجازی، منتشر شد.
(2016) AlphaGo از Google DeepMind، قهرمان جهان Go Lee Sedol را شکست داد. پیچیدگی بازی باستانی چینی به عنوان یک مانع بزرگ برای رفع در هوش مصنوعی تلقی میشد.
(2016) اولین شهروند رباتی، یک ربات انسان نما به نام سوفیا، توسط Hanson Robotics ساخته شده و قادر به تشخیص چهره، ارتباط کلامی و بیان چهره است.
(2018) گوگل موتور پردازش زبان طبیعی BERT را منتشر کرد که موانع ترجمه و درک توسط برنامه های ML را کاهش میداد.
(2018) Waymo سرویس Waymo One خود را راهاندازی کرد و به کاربران این امکان را میداد که در سرتاسر منطقه شهری فونیکس درخواست دریافت یکی از خودروهای خودران این شرکت کنند.
دهه 2020
(2020) بایدو الگوریتم LinearFold AI خود را برای تیمهای علمی و پزشکی که برای توسعه واکسن در مراحل اولیه همهگیری SARS-CoV-2 کار میکنند، منتشر کرد. این الگوریتم قادر است توالی RNA ویروس را تنها در 27 ثانیه پیش بینی کند که 120 برابر سریعتر از روشهای دیگر است.
(2020) OpenAI مدل پردازش زبان طبیعی GPT-3 را منتشر کرد که قادر بود متنی را با الگوبرداری از نحوه صحبت و نوشتن افراد تولید کند.
(2021) OpenAI بر روی GPT-3 برای توسعه DALL-E ساخته شد، که قادر به ایجاد تصاویر از پیامهای متنی است.
(2022) موسسه ملی استانداردها و فناوری اولین پیش نویس چارچوب مدیریت ریسک هوش مصنوعی خود را منتشر کرد. (دستورالعمل داوطلبانهی ایالات متحده “برای مدیریت بهتر خطرات برای افراد، سازمان ها و جامعه مرتبط با هوش مصنوعی”).
(2022) DeepMind از Gato، یک سیستم هوش مصنوعی آموزش دیده برای انجام صدها کار، از جمله پخش آتاری، شرح تصاویر و استفاده از یک بازوی رباتیک برای چیدن بلوک ها، رونمایی کرد.
شرح تفاوت هوش مصنوعی و ماشین لرنینگ و دیپ لرنینگ:
تصویر زیر نمایی کلی از جایگاه هوش مصنوعی، یادگیری ماشین و یادگیری عمیق را به شما نشان میدهد.
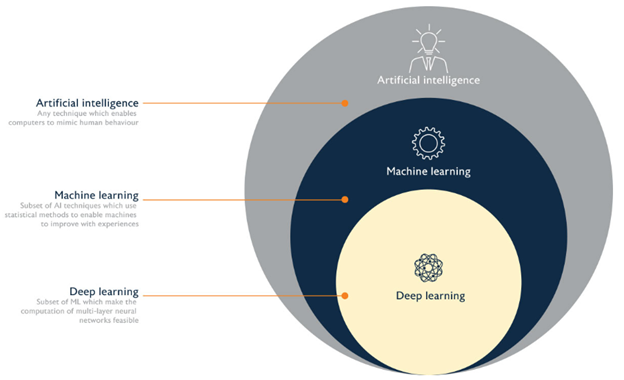
همانطور که در تصویر بالا مشاهده میکنید یادگیری ماشین بخشی از هوش مصنوعی است، آنچه که در ابتدا دربارهی آن صحبت کردیم این بود که هوش مصنوعی مجموعهای از قوانین از پیش تعیین و تعریف شده بود که رفتاری انسانی را شبیه سازی میکرد، در مثال کلاسیک شطرنج، فرض کنید کامپیوتر در حالت کیش قرار گرفته است اتفاقی که میافتد: هوش مصنوعی اطلاعات اینکه در حالت کیش قرار دارد را به کامپیوتر انتقال میدهد سپس مجموعهی قوانین خود را بررسی میکند و داده ی دریافت شده را تحلیل و آنالیز میکند، تشخیص میدهد در حالت کیش قرار دارد و تصمیم میگیرد مهره ی خود را به چه خانهای انتقال دهد. این سؤال طرح میشود که ماشین لرنینگ در چه مرحلهای از این فرآیند نقش ایفا میکند؟
یادگیری ماشین در واقع اولین زمینهای است که با توجه به دادههای ورودی، پس از تجزیه و تحلیل قوانین را استخراج میکند در نتیجه دیگر نیاز به برنامه نویسی قوانین توسط انسانها در این مرحله وجود ندارد. احتمالاً شنیدهاید که یادگیری ماشین به حجم قابل توجهای از دادهها نیاز دارد، در واقع دیتاهای ورودی شما بهترین مدل برای تکامل یادگیری ماشین هستند و هر چه دیتایی که به کامپیوتر میدهید بزرگتر باشد، کشف و آنالیز الگوریتمها و قوانین را برای یادگیری ماشین آسانتر میکند. علت این موضوع این است که یادگیری ماشین قوانین را برای ما ایجاد میکند، ما مجموعهای از اطلاعات ورودی به او میدهیم و نتایج خروجی را نیز مشخص میکنیم و ماشین لرنینگ با توجه به این فاکتورها قوانین را برای ما جهت رسیدن به خروجی مشخص استخراج میکند. در حال حاضر با توجه به حجم زیاد دادههای اکثر مواقع یادگیری ماشین دقت 100٪ ندارند به این معنا که لزوماً هر بار به قوانین و پاسخ درست دست پیدا نمیکنند. هدف ما از ایجاد یادگیری ماشین این است که تا حد ممکن میزان دقت را افزایش دهیم تا کمترین میزان اشتباه را به همراه داشته باشیم.
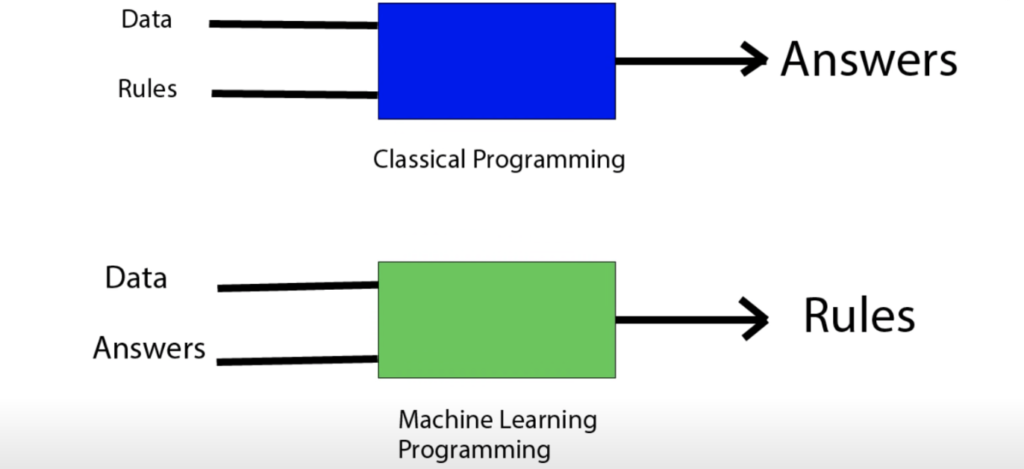
تفاوت هوش مصنوعی و یادگیری ماشین چیست؟
با توجه به آنچه گفته شد، برخلاف هوش مصنوعی که برنامهنویسان پروسه و قوانین را از پیش تعریف میکنند در یادگیری ماشین ما با دریافت مجموعهی داده و نتایج مورد نظر، قوانین را برای ما کشف و استخراج میکند.
یادگیری عمیق (Deep learning) و شبکههای عصبی (Artificial neural network) چیست؟
سادهترین راه برای توصیف یک شبکهی عصبی این است: فرمی از یادگیری ماشین از روش نمایش لایهای داده استفاده میکند.نام و ساختار دیپ لرنینگ از مغز انسان الهام گرفته شده است و از روشی که نورونهای بیولوژیکی مغز انسان به یکدیگر سیگنال میدهند تقلید میکند.نکتهی قابل توجه این است که شبکههای عصبی از مغز مدل برداری نشدهاند در حالی که تصور عموم مردم این است که لایهها و شبکهها در یادگیری عمیق بر مبنای شبکههای مغز انسان الگوریتم و مبنا گذاری شدهاند. تنها اسم و ساختار کلی دیپ لرنینگ از مغز انسان الهام گرفته شده است و هیچ گونه الگو برداری از نحوه عملکرد مغز و نورونها در شبکههای عصبی صورت نگرفته است.
در یادگیری عمیق ما یک لایهی ورودی داریم، که اولین لایه از دیتا میباشد و یک لایه خروجی داریم، توجه کنید که در بین لایههای اصلی ما لایههای دیگری نیز میتوانند وجود داشته باشند.بنابراین آنچه اتفاق میافتد این است که دادههای ما از لایههای متفاوت انتقال و تکامل پیدا میکنند که تغییراتی به دنبال هر یک از این انتقالها و ارتباطات به دنبال خواهد داشت.اطلاعات با گذر از هر لایه از شبکههای عصبی بر مبنای یک سری قوانین از ویژگیها و ابعاد مختلف مورد بررسی قرار میگیرند و به شکل دیگری از خود تبدیل میشوند. در نهایت در لایهی نهایی و خروجی تمام اطلاعات و ارتباطات بدست آمده از دادهی ورودی به صورت یک نتیجهی معنادار با توجه به اهداف هوش مصنوعی دریافت میکنیم، اکثراً این روش از تحلیل و بازبینی دیتا را فرآیند استخراج چند مرحلهای اطلاعات (Multi-Stage Information Processing) مینامند.
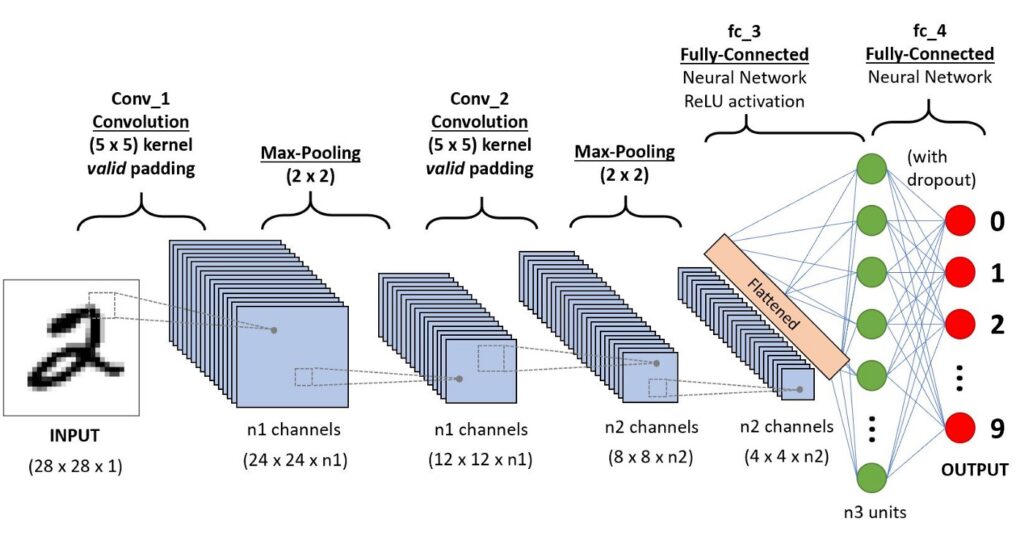
تفاوت یادگیری ماشین، یادگیری عمیق و هوش مصنوعی به صورت خلاصه و به زبان ساده:
در یادگیری ماشین تنها دو لایه از اطلاعات وجود دارد: لایهی ورودی و خروجی. در حالی که در یادگیری عمیق، شبکهای از لایههای جهت بررسی و آنالیز داده وجود دارد و در هوش مصنوعی لایههایی از پیش تعریف شده جهت بررسی و تحلیل دیتا وجود ندارد.
در جدول زیر نگاهی به تفاوتهای عمده در عملکرد یادگیری عمیق و ماشین لرنینگ میاندازیم:
| Deep Learning | Machine Learning |
| زیرمجموعهای از یادگیری ماشین است | زیر مجموعهای از هوش مصنوعی است |
| میتواند با استفاده از مجموعه دادههای کوچکتر آموزش ببیند | به مقادیر زیادی داده نیاز دارد |
| برای تصحیح و یادگیری به خودی خود از محیط و اشتباهات گذشته یاد میگیرد | آموزش کوتاهتر و دقت کمتر در مقابل تمرین طولانی تر و دقت بالاتر |
| همبستگیهای ساده و خطی ایجاد می کند | همبستگیهای غیرخطی و پیچیده ایجاد میکند |
| میتواند روی CPU (واحد پردازش مرکزی) آموزش ببیند | برای آموزش به GPU (واحد پردازش گرافیکی) تخصصی نیاز دارد. |
اهمیت دیتا در هوش مصنوعی، یادگیری ماشین و دیپ لرنینگ:
دادهها مهمترین و ضروریترین منبع برای یادگیری ماشین (Deep Learning) هستند. منظور از دیتا میتواند هر واقعیت، متن، نماد، تصوی، فیلم و… باشد، اما اطلاعاتی به شکل پردازش نشده. هنگامی که دادهها پردازش میشوند، به عنوان اطلاعات توسط کامپیوتر شناخته میشوند. یادگیری ماشینی بدون داده ماهیت و وجودی از خود ندارد جز یک ماشین خالی و بدون ذهن. این دادهها باعث میشود ماشینها کارهای شگفتانگیزی را انجام دهند که چند سال پیش در تاریخ به آن فکر نکرده بودیم.
علیرغم داشتن چنین اهمیتی، ماشینها نمیدانند که دادهها چه چیزی را نشان میدهند. آنها نمیدانند که چرا «الف»، «الف» است و چرا به این شکل نوشته شده است یا چرا «این» به معنای آن است. بسیاری از ما غذایی که می خوریم را درک نمیکنیم، تنها چیزی که میدانیم این است که باید بخوریم و این کار را میکنیم. ما به پس زمینه و پیش زمینه اهمیت نمیدهیم. دادههای یادگیری ماشینی همانند غذا هستند. ماشین صرفاً آنها را مصرف میکند و سپس به جای درک دادهها، روابط بین دادههای مختلف را یاد میگیرد و ارائه میدهد.
بنابراین اساساً، تمام مسئولیت ماشینها، یافتن روابط بین دادههای مختلف است. در این قسمت به این موضوع میپردازیم که چرا دادهها مهم هستند و چگونه ماشینها ماهیت دادهها را نمیفهمند اما روابط بین دادهها را پیدا میکنند.
ارزش داده ها برای یادگیری ماشین چیست؟
داده برای یادگیری ماشین بسیار مهم است و بدون داده، یادگیری ماشین ممکن نیست. همانطور که تجربیات انسانی در زندگیاش نقش مهمی ایفا میکند به همین ترتیب، دادههای یادگیری ماشینی برای رشد تجربه و توانایی آن در تصمیمگیری بر اساس دادههایی که به آن داده میشود، مهم است. این داده ها برای یادگیری ماشینی می توانند دو نوع باشند:
دادههای عددی
این نوع داده ها به صورت اعداد میباشند و در این نوع مجموعه همهی دادهها به شکل اعداد تبدیل شدهاند. این یک نوع داده خوب و قابل استناد است و همه مدل های یادگیری ماشینی با دادههایی از این نوع کار می کنند. همه انواع دادههای دیگر باید به این فرم ترجمه شوند، و سپس آن دادهها به دستگاه وارد میشوند، دادههایی مانند: سن، حقوق، تجربه و غیره.
دادههای طبقه بندی شده
دیتای طبقه بندی شده نوع دیگری از داده است. معمولاً دادههایی که شامل کاراکترهایی مانند متن، نمادها و… هستند در این دسته قرار میگیرند. این نوع دادهها در درجه اول بسیار مهم است که با استفاده از برخی تکنیکها به شکل عددی تبدیل شوند. تا زمانی که تبدیل به دیتای عددی نشوند ، ماشین نمیتواند این دادهها را بگیرد و روابط بین داده های ورودی و خروجی را فرموله کند. هنگام برخورد با این نوع داده ها، مهم است که این نکته را در نظر داشته باشید. به یاد داشته باشید: همیشه داده های دسته بندی را به داده های عددی تبدیل کنید
چه مقدار داده باید وجود داشته باشد؟
این سؤال یکی از نکتههای ضروری است که باید در هنگام کار با یادگیری ماشین در نظر گرفت، به خاطر داشته باشید باید دادههای کافی داشته باشیم تا دستگاه از دچار کمبود دیتا نشود.
یک نکته بسیار مهم: کمیت کم و زیاد هر دو برای ماشینها و همچنین برای انسان و همه موجودات مضر است، پس در نظر گرفتن میزان دادهی مورد نیاز ماشین جهت انجام پروژه مقولهی بسیار مهمی است.
گاهی اوقات ما دادههای بسیار کمی داریم و با کمبود دیتا مواجه هستین در این مواقع باید دادههای بیشتری به دست آوریم. تکنیک های مختلفی برای به دست آوردن اطلاعات بیشتر وجود دارد.
اولین قدم باید به دست آوردن دادهها به صورت دستی است، که میتواند از طریق نظرسنجی، پرسشنامه و غیره باشد. اگر چنین چیزی امکان پذیر نیست، تکنیکهای دیگری برای رفع کمبود دیتای ورودی وجود دارد.
بهترین پلتفرمهای موتور جستجو مجموعه داده در چالش فراهم کردن منابع مورد نیاز یادگیری ماشین
در قسمت زیر لیستی از چند پلتفرم مجموعه داده آمده است که به شما این امکان را میدهد تا دادهها را برای پروژهها و آزمایشهای یادگیری ماشین جستجو و دانلود کنید. اکثر مجموعه دادهها قبلاً برای پروژههای ماشین لرنینگ (ML) و هوش مصنوعی (AI) تمیز و جدا شدهاند. با این حال، باید آنها را با توجه به مشخصات خود فیلتر کنید و سپس از خروجیهای بدستآمده استفاده کنید.
موتور جستجوی مجموعه داده های گوگل
مجموعه داده های Kaggle
ZDataset Free -Dataset
مخزن یادگیری ماشین UCI
مجموعه دادههای ICPSR
Data World
gesisDataSearch
دیتاسرویس انگلستان
انواع مختلف یادگیری ماشین:
به صورت کلی ماشین لرنینگ را بر اساس انوع روش و مسیر برای یادگیری به ۳ دسته تقسیم میکنند:

تفاوت یادگیری سوپروایز شده و یادگیری سوپروایز نشده چیست؟
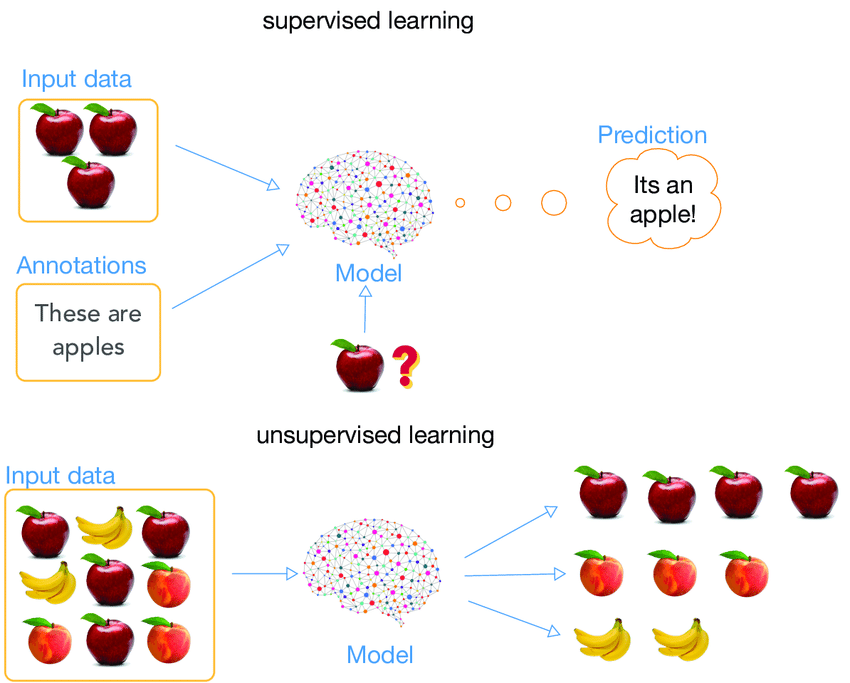
یادگیری تحت نظارت:
یادگیری نظارت شده زمانی است که مدل بر روی یک مجموعه داده برچسبدار آموزش میبیند. مجموعه داده برچسبگذاری شده مجموعهای است که دارای پارامترهای ورودی و خروجی است.
آموزش سیستم: در حین آموزش مدل، دادهها معمولاً به نسبت 80:20 یعنی 80 درصد به عنوان دادههای آموزشی و بقیه به عنوان دادههای آزمایشی تقسیم میشوند. در دیتاهای آموزشی، ورودی و همچنین خروجی را برای 80 درصد دادهها در نظر میگیریم. مدل انتظاری ما فقط بر طبق دادههای آموزشی ساخته میشود. در این روش ماشین از الگوریتمهای مختلف ماشین لرنینگ برای ساخت مدل خود استفاده میکند. یادگیری به این معنی است که هوش مصنوعی یک مدل منطقی با توجه به دادههای بررسی شده برای خود ایجاد خواهد کرد.
پس از آماده شدن مدل، عموماً آن را آزمایش میکنند. در زمان آزمایش، ورودی از 20 درصد باقیمانده دادههایی که هوش مصنوعی قبلاً هرگز ندیده است، در این زمان پس از دریافت این دسته از دیتا، ماشین مدل حدود را پیشبینی میکند و ما آن را با خروجی واقعی مقایسه میکنیم و دقت ماشین را محاسبه میکنیم.
طبقه بندی: این یک کار یادگیری نظارت شده است که در آن خروجی دارای برچسبهای تعریف شده (مقدار گسسته) است. به عنوان مثال ا، خروجی – خریداری شده دارای برچسب های تعریف شده است، یعنی 0 یا 1. 1 به این معنی است که مشتری خرید خواهد کرد و 0 به این معنی است که مشتری خرید نخواهد کرد. هدف در اینجا پیش بینی مقادیر گسسته متعلق به یک دسته خاص و ارزیابی آنها بر اساس دقت است.
ماشین میتواند طبقهبندی باینری یا چندطبقهای باشد. در طبقهبندی باینری، مدل 0 یا 1 را پیش بینی میکند. بله یا خیر، اما در مورد طبقه بندی چندطبقه، مدل بیش از یک حالت را پیش بینی می کند. مثال: Gmail نامهها را در بیش از یک نوع مانند اجتماعی، تبلیغات، بهروزرسانیها و انجمنها طبقهبندی میکند.
رگرسیون: یک نوع روش کار یادگیری نظارت شده است که در آن خروجی دارای ارزش پیوسته است.
به عنوان مثال: خروجی یا سرعت باد هیچ مقدار گسستهای ندارد اما در یک محدوده خاص پیوسته است. هدف در اینجا پیشبینی مقداری تا حدی است که مدل ما میتواند به مقدار خروجی واقعی نزدیکتر باشد و سپس ارزیابی با محاسبه مقدار خطا انجام میشود. هر چه خطا کوچکتر باشد، دقت مدل رگرسیون ما بیشتر است.
نمونهای از الگوریتمهای یادگیری نظارت شده:
رگرسیون خطی (Linear Regression)
رگرسیون لجستیک (Logistic Regression)
نزدیکترین همسایه (K_nearest neighbor algorithm)
بیز گاوسی (Naive Bayes Classifier)
درختان تصمیم (Decision Tree)
Support verctor machine (SVM)
Linear discriminant analysis
کاربردهای یادگیری تحت نظارت(supervised learning)
پیشبینی قیمت املاک و مستغلات
طبقهبندی اینکه آیا تراکنشهای بانکی تقلبی هستند یا خیر
یافتن عوامل خطر بیماری
تعیین اینکه متقاضیان وام کم ریسک یا پرخطر هستند
پیشبینی خرابی قطعات مکانیکی تجهیزات صنعتی
یادگیری بدون نظارت:
یادگیری بدون نظارت، آموزش ماشینی با استفاده از اطلاعاتی است که نه طبقهبندی شده و نه برچسبگذاری شده است و به الگوریتم و ماشین اجازه میدهد تا بر روی آن اطلاعات بدون راهنمایی عمل کند. در اینجا وظیفه ماشین گروهبندی اطلاعات مرتب نشده بر اساس شباهتها، الگوها و تفاوتها بدون آموزش قبلی دربارهی دادهها است.
بر خلاف یادگیری تحت نظارت، هیچ قوانین و اطلاعات از پیش تعیین شدهای در این پروسه ارائه نمیشود که به این معنی است که هیچ آموزشی به ماشین داده نخواهد شد. بنابراین ماشین محدود شده است تا ساختار پنهان در دادههای بدون برچسب را به خودی خود پیدا کند.
به عنوان مثال، فرض کنید تصویری از سگ و گربه به آن داده شده است که هرگز ندیده است.
بنابراین دستگاه هیچ ایدهای در مورد ویژگیهای سگ و گربه ندارد، بنابراین ما نمیتوانیم آن را به عنوان “سگ و گربه” دستهبندی کنیم. اما میتواند آنها را بر اساس شباهتها، الگوها و تفاوتهایشان دستهبندی کند، یعنی به راحتی میتوانیم تصویر بالا را به دو قسمت دستهبندی کنیم. قسمت اول ممکن است شامل تمام عکسهایی باشد که در آنها سگ وجود دارد و قسمت دوم ممکن است شامل تمام عکسهایی باشد که در آنها گربه وجود دارد.
این روش به ماشین اجازه می دهد تا برای کشف الگوها و اطلاعاتی که قبلاً شناسایی نشده بودند، به تنهایی کار کند. و عمدتاً با دادههای بدون برچسب سروکار دارد.
یادگیری بدون نظارت به دو دسته الگوریتم طبقه بندی میشود:
خوشه بندی: یک مشکل خوشهبندی مدلی است که میخواهید گروه بندیهای بنیادی را در دادهها را کشف کنید، مانند گروهبندی مشتریان بر اساس رفتارشان در خرید.
ارتباط: مشکل یادگیری قوانین تداعی جایی است که ماشین بخواهد قوانینی را کشف کند که بخشهای بزرگی از دادههای شما را توصیف میکنند، مانند افرادی که X را خریداری میکنند و نیز تمایل به خرید Y دارند.
انواع یادگیری بدون نظارت:
Exclusive (partitioning)
AgglomerativeOverlapping
Probabilistic
انواع کلاسترینگ (Clustering Types):
Hierarchical clustering
K-means clustering
Principal Component Analysis
Singular Value Decomposition
Independent Component Analysi
کاربردهای یادگیری بدون نظارت(unsupervised learning)
ایجاد گروههای مشتری بر اساس انتخابهای گذشته در خرید
گروهبندی موجودی بر اساس معیارهای فروش و یا تولید
مشخص کردن ارتباط در دادههای مشتری (به عنوان مثال، مشتریانی که سبک خاصی از کیف دستی میخرند ممکن است به سبک خاصی از کفش علاقه داشته باشند)
سخن آخر:
محتوایی که مطالعه کردید، بدون ورود به مباحث تخصصی توصیف جامع و سادهای از هوش مصنوعی و مفاهیم زیر مجموعههای آن بود، امیدوارم برایتان نقطهی شروع خوبی در این مسیر بوده باشد.